WebAssembly fait parler de lui, y compris en dehors du navigateur. Cet engouement n’est pas seulement lié à un environnement d’exécution WebAssembly isolé mais aussi parce qu’on peut exécuter du code WebAssembly depuis des langages comme Python, Ruby ou Rust.
Pour quoi faire ? Voici quelques raisons :
- Rendre les modules « natifs » moins compliqués
Les environnements d’exécution tels que Node ou CPython pour Python permettent également d’écrire des modules dans des langages bas niveau tels que C++. Une telle approche permet de profiter de la vitesse de ces langages bas niveaux. On peut ainsi utiliser des modules natifs en Node ou des modules d’extension en Python. Toutefois ces modules sont souvent difficiles à utiliser car ils doivent être compilés sur l’appareil de l’utilisateur. Avec un module « natif » WebAssembly, on obtient une bonne partie de cette vitesse sans compliquer la mise en œuvre. - Isoler plus facilement le code natif dans des bacs à sable
D’un autre côté, pour des langages bas niveau tels que Rust, pas besoin d’utiliser WebAssembly pour gagner de la vitesse. En revanche, cela peut servir pour la sécurité. Comme nous en parlions lors de l’annonce de WASI, WebAssembly fournit un bac à sable léger par défaut et un langage comme Rust pourrait utiliser WebAssembly afin de placer ses modules natifs dans un bac à sable. - Partager du code natif à travers différentes plateformes
Les développeurs peuvent s’épargner du temps et des coûts de maintenance s’ils peuvent réutiliser la même base de code sur différentes plateformes (entre une application web et une application pour le bureau par exemple). Cela concerne aussi bien les langages de script que les langages bas niveaux. De plus, WebAssembly apporte une solution sans ralentir quoi que ce soit sur les plateformes en question.

WebAssembly pourrait donc aider d’autres langages à résoudre des problèmes majeurs.
Malgré cela, convertir une valeur d’un type vers l’autre est possible en suivant certaines règles cette façon. WebAssembly peut être exécuté dans ces environnements mais ce n’est pas suffisant.
Aujourd’hui, WebAssembly ne dialogue avec l’extérieur qu’avec des nombres et ses fonctions peuvent être appelées depuis un autre langage et vice versa.
Mais si une fonction prend des arguments ou renvoie une valeur qui ne sont pas des nombres, ça devient vite compliqué. On peut alors :
- Mettre à disposition un module dont l’API est ultra-compliqué et ne manipule que des nombres : tant pis pour l’utilisateur du module…
- Ajouter du code intermédiaire (de la « glue ») pour chaque environnement dans lequel on souhaite que ce module puisse être exécuté : tant pis pour le développeur du module.
Faut-il s’en satisfaire ?
On devrait pouvoir fournir un seul module WebAssembly qui puisse être exécuté n’importe où… sans pour autant compliquer la vie de l’utilisateur du module ou de son développeur.

Le même module WebAssembly pourrait utiliser des API riches et des types complexes afin de dialoguer avec :
- Des modules s’exécutant dans leur environnement natif (ex. des modules Python s’exéutant dans un environnement Python)
- D’autres modules WebAssembly écrits depuis d’autres langages sources (ex. un module Rust et un module Go s’exécutant de concert dans le navigateur)
- Le système sous-jacent (ex. un module WASI fournissant une interface système avec le système d’exploitation ou avec les API du navigateur).
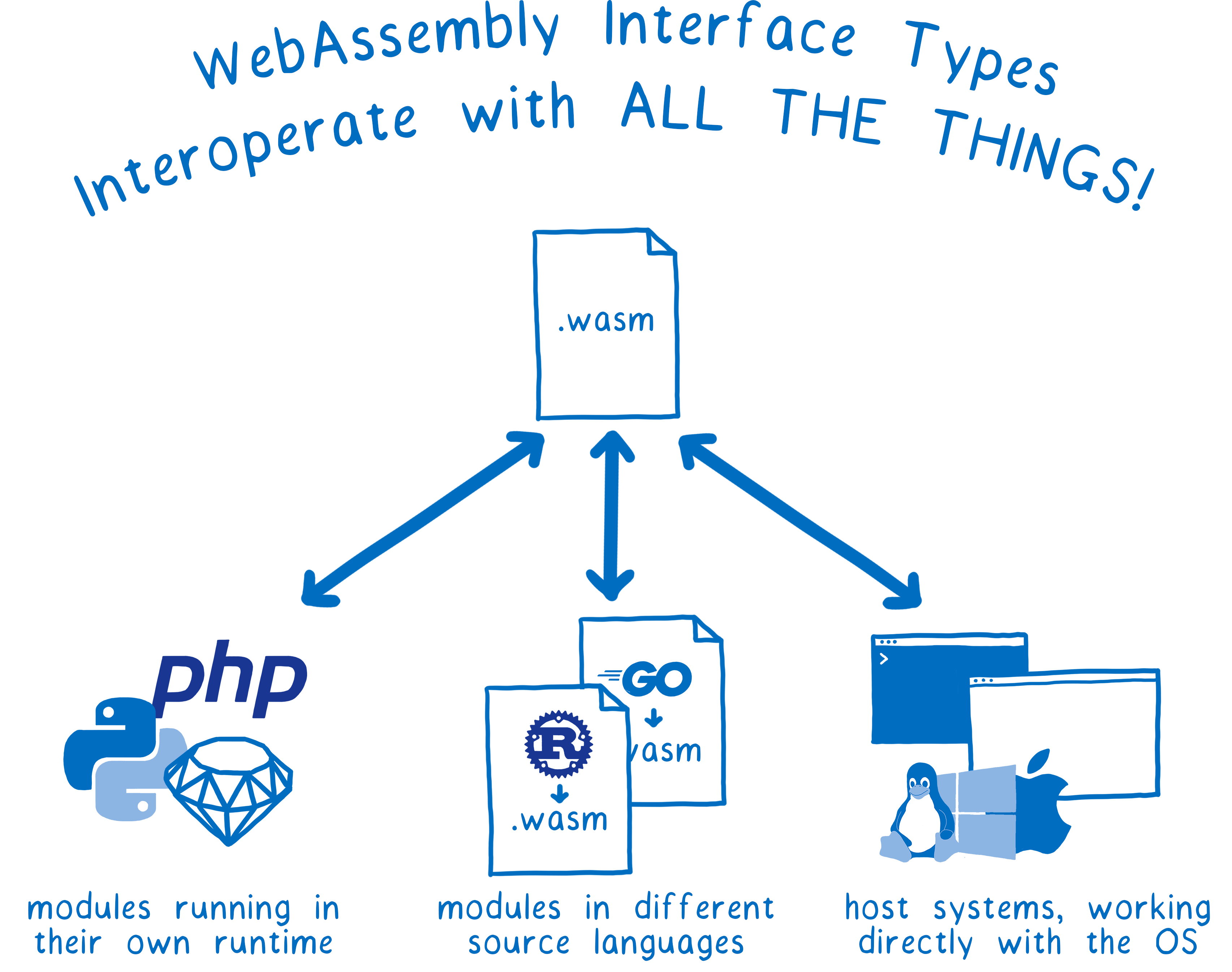
Avec une nouvelle proposition, nous pouvons voir comment cela peut fonctionner (et ça fonctionne :)). Voici par exemple une démo :
Voyons comment cela fonctionne. Mais avant regardons la situation actuelle et les problèmes que nous essayons de résoudre.
Discussion entre WebAssembly et JavaScript
WebAssembly ne se limite pas au Web mais jusqu’à présent, une grande partie du développement de WebAssembly concernait le Web.
En effet, on conçoit mieux lorsqu’on se concentre sur la résolution de problèmes concrets. Ce langage devait être exécuté sur le Web et c’était donc un point de départ pertinent.
On a ainsi obtenu un produit minimum viable (MVP) avec un périmètre bien défini. WebAssembly devait alors seulement être capable de dialoguer avec un autre langage : JavaScript.
Ce fut relativement facile à obtenir. Au sein du navigateur, WebAssembly et JS s’exécutent dans le même moteur et le moteur peut donc les aider à discuter efficacement.

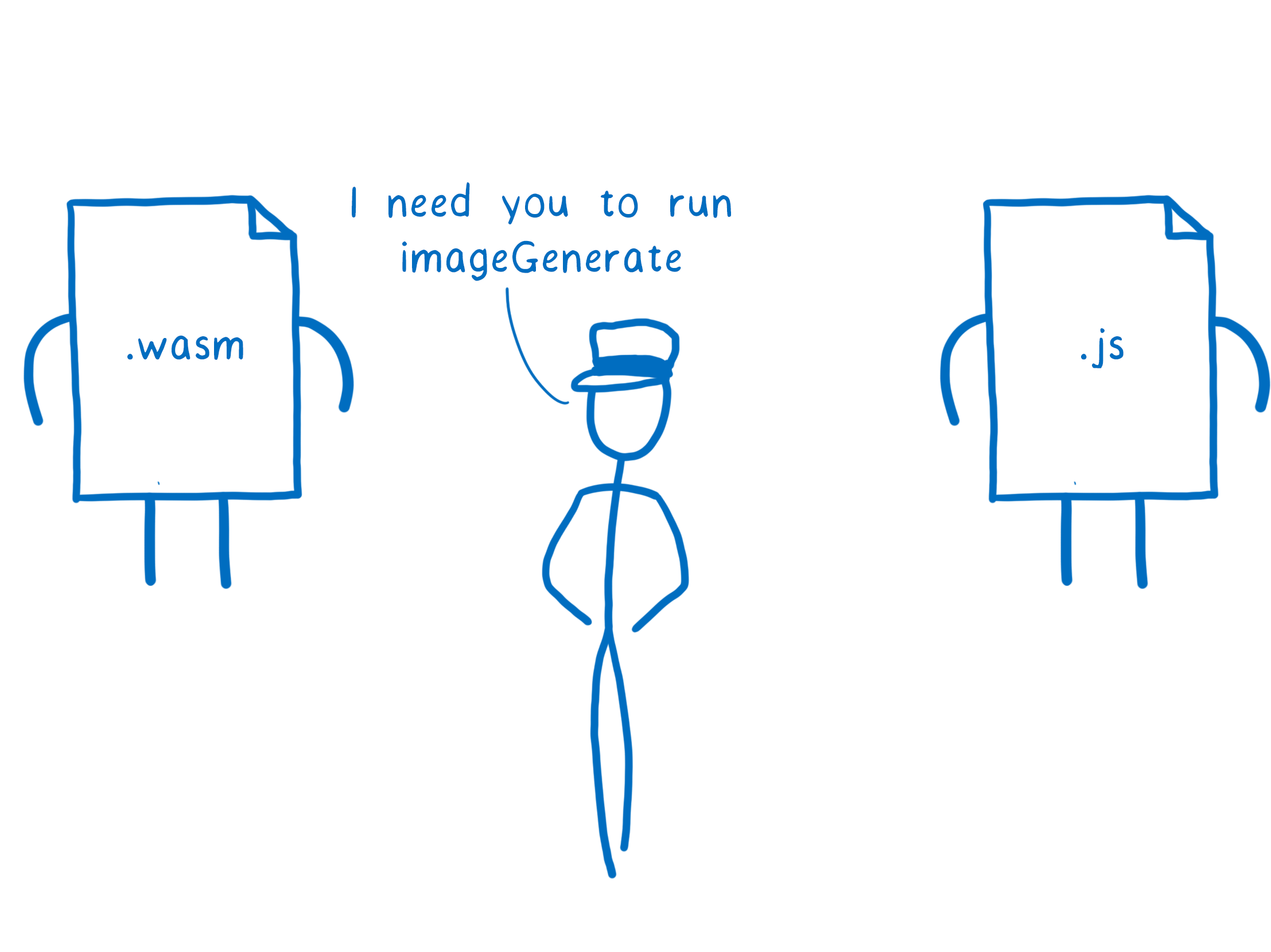
Malgré tout, il y a un problème lorsque ces deux-là essaient de dialoguer : ils utilisent des types différents.
Actuellement, WebAssembly ne s’exprime qu’avec des nombres. JavaScript sait ce qu’est un nombre mais possède également quelques autres types.
Et même les nombres ne sont pas vraimeent les mêmes. WebAssembly possède quatre types de nombres : int32, int64, float32, float64. JavaScript possède quant à lui un seul type Number (BigInt sera bientôt un nouveau type numérique en JS).
La différence entre ces types ne s’arrête pas aux noms. Les valeurs sont aussi stockées différemment en mémoire.
Pour commencer, n’importe quelle valeur JavaScript (quel que soit son type) est placée dans une boîte (voir ce précédent article où j’expliquais le concept).
En revanche, WebAssembly utilise des types statiques pour les nombres et il n’utilise ni ne comprend les boîtes de JavaScript.
Cette différence rend le dialogue un peu compliqué.
 Malgré cela, convertir une valeur d’un type vers l’autre est possible en suivant quelques règles simples.
Malgré cela, convertir une valeur d’un type vers l’autre est possible en suivant quelques règles simples.
Les règles simples sont facilement écrites et on peut les retrouver dans la spécification de l’API entre WebAssembly et JavaScript.

Cette correspondance est inscrite dans les moteurs d’exécution.
C’est un peu comme si le moteur possédait un manuel. Lorsque le moteur doit passer des paramètres ou des valeurs de retour entre JavaScript et WebAssembly, il sort le manuel et le consulte afin de savoir comment convertir ces valeurs.

Avoir aussi peu de types à gérer (uniquement des nombres) rend la chose facile. Ce fut une bonne chose pour un MVP et ça a réduit le nombre de questions difficiles à trancher.
En contrepartie, ce fut plus compliqué pour les développeurs d’utiliser WebAssembly. Pour passer des chaînes de caractères entre JavaScript et WebAssembly, il a fallu trouver une méthode pour transformer des chaînes de caractères en tableaux de nombres puis de faire l’opération inverse. Nous avions couvert sur ce sujet dans un précédent billet.

Ce n’est pas difficile mais c’est laborieux. Des outils ont naturellement été construits afin de rendre cette conversion transparente.
Entre autres, on pourra trouver des outils tels que wasm-bindgen (en Rust) et Embind d’Emscripten qui enveloppent automatiquement le module WebAssembly avec du code JavaScript de liaison qui s’occupe de la traduction des chaînes de caractères en nombres.
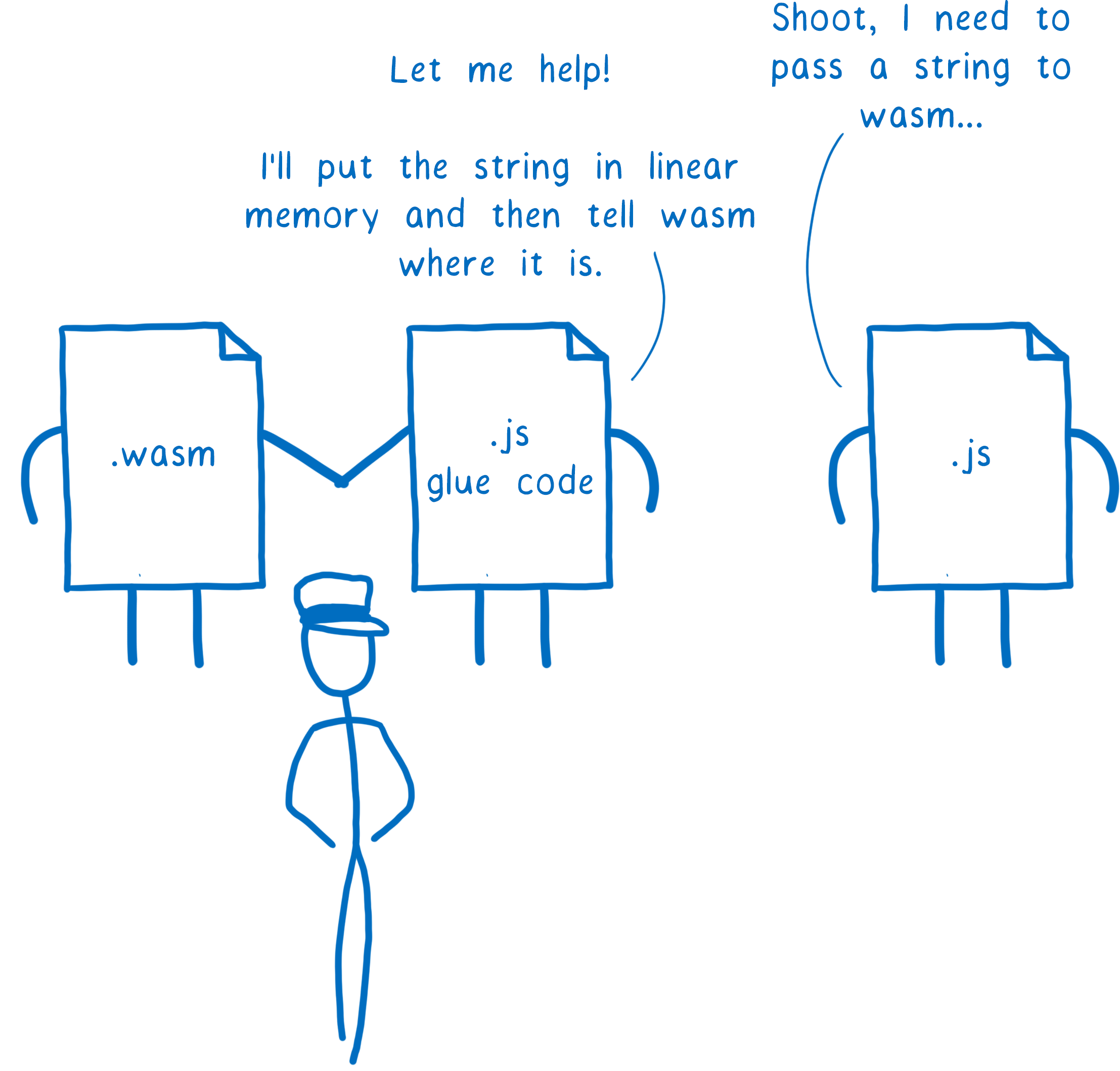 Ces outils ont également permis d’effectuer des transformations pour des types de plus haut niveau comme des objets complexes avec des propriétés.
Ces outils ont également permis d’effectuer des transformations pour des types de plus haut niveau comme des objets complexes avec des propriétés.
Cela fonctionne mais pour certains cas triviaux, ce n’est pas suffisant.
Imaginons qu’on veuille passer une chaîne de caractères entre deux scripts JS via un module WebAssembly. On doit avoir une fonction JavaScript qui passe une chaîne à une fonction WebAssembly puis le module WebAssembly doit passer cette chaîne à une autre fonction JavaScript.
Pour que tout cela fonctionne, il faut :
- Que la première fonction JavaScript passe la chaîne de caractères au code JS qui s’occupe de la liaison (“glue code”)
- Que le code de liaison transforme cette chaîne de caractères en nombre et passe ces nombres en mémoire linéaire
- Qu’il envoie un nombre (le pointeur vers le début de la zone mémoire) au module WebAssembly
- Que la fonction WebAssembly passe ce nombre au code de liaison JS de l’autre côté
- Que le code de liaison JavaScript retire ces nombres de la mémoire linéaire pour les décoder en chaîne de caractères
- Que le deuxième script de liaison fournisse cette chaîne à la deuxième fonction JS.

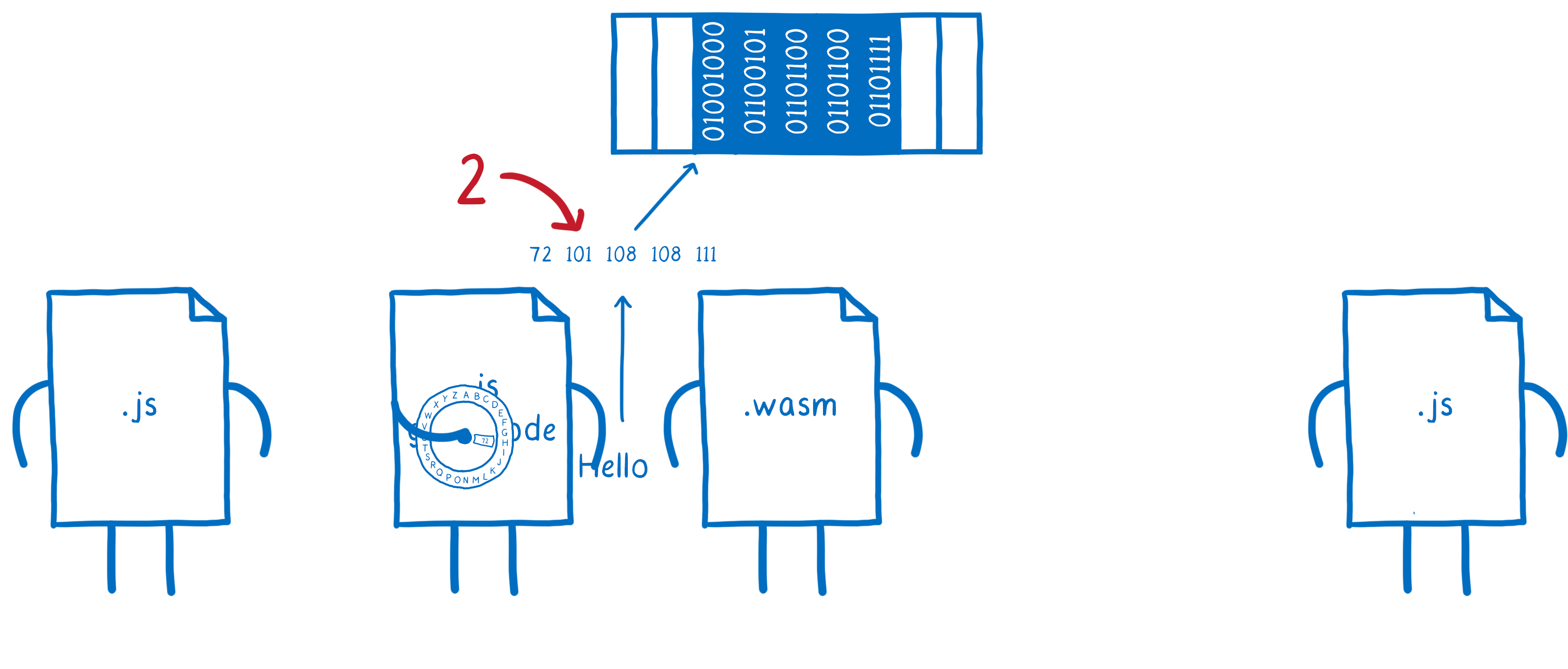
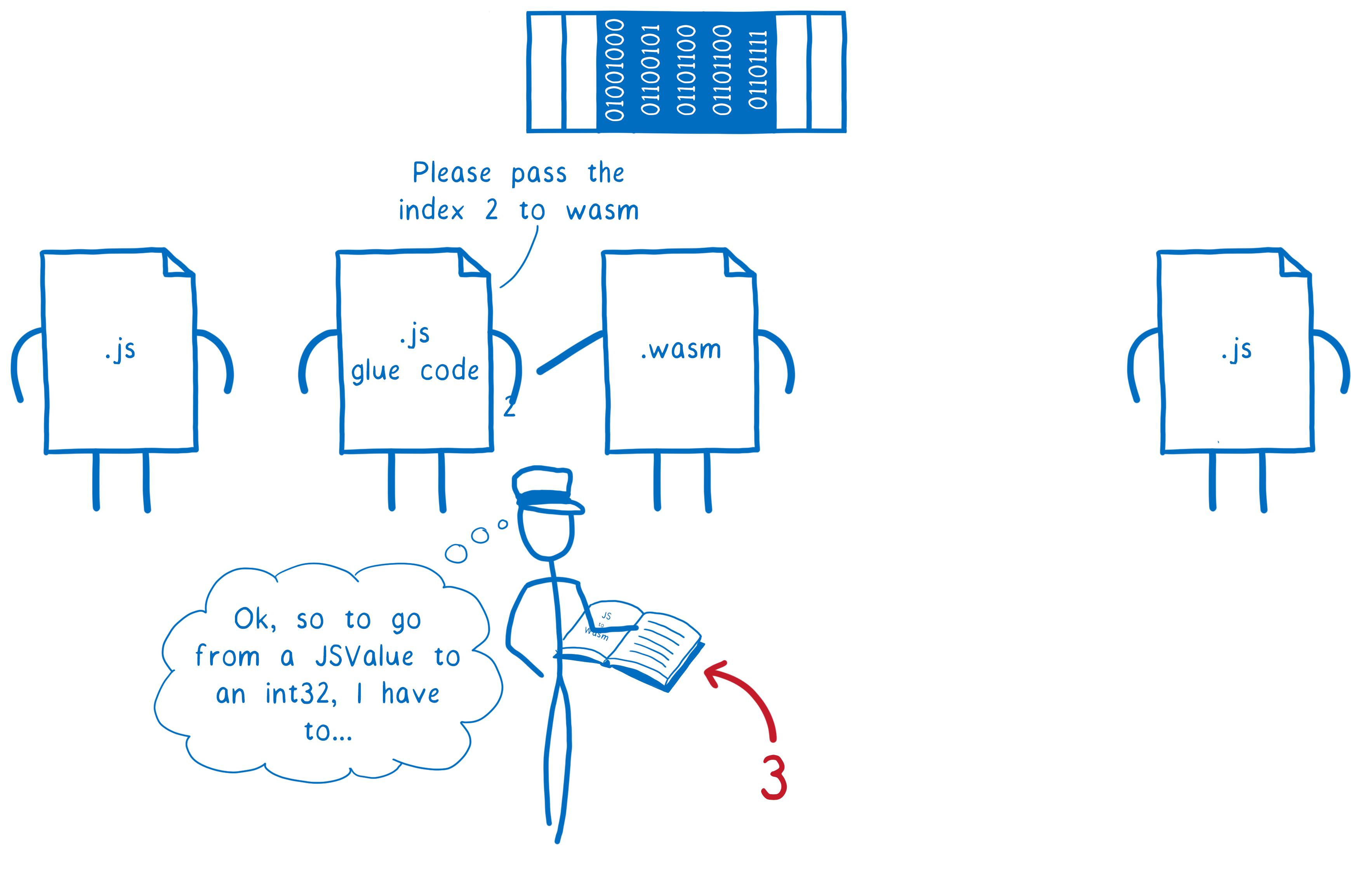
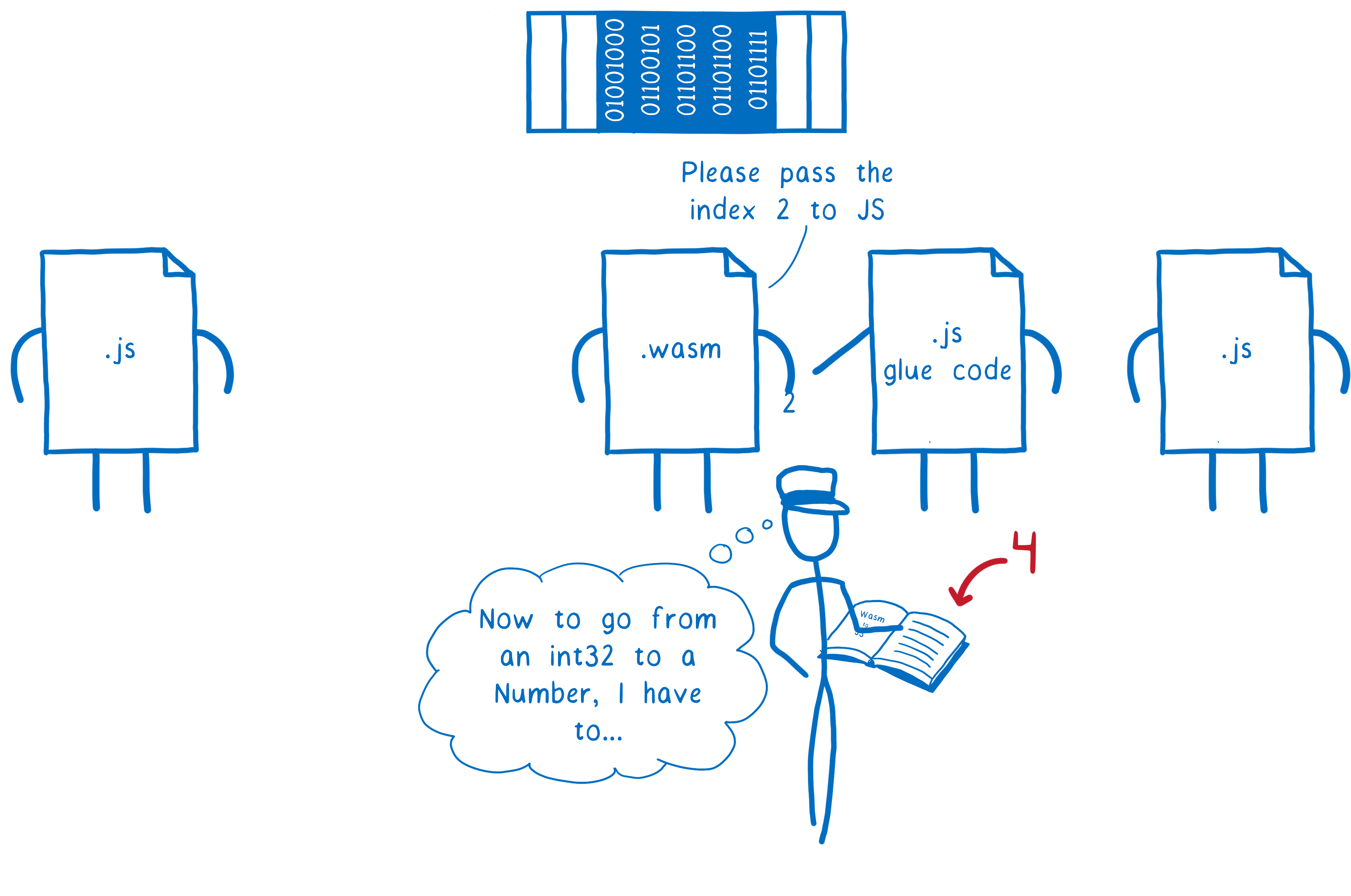


On a donc un code de liaison JS qui effectue “simplement” l’opération inverse de celle effectuée plus tôt pour la conversion. Cela fait beaucoup de travail pour en arriver là.
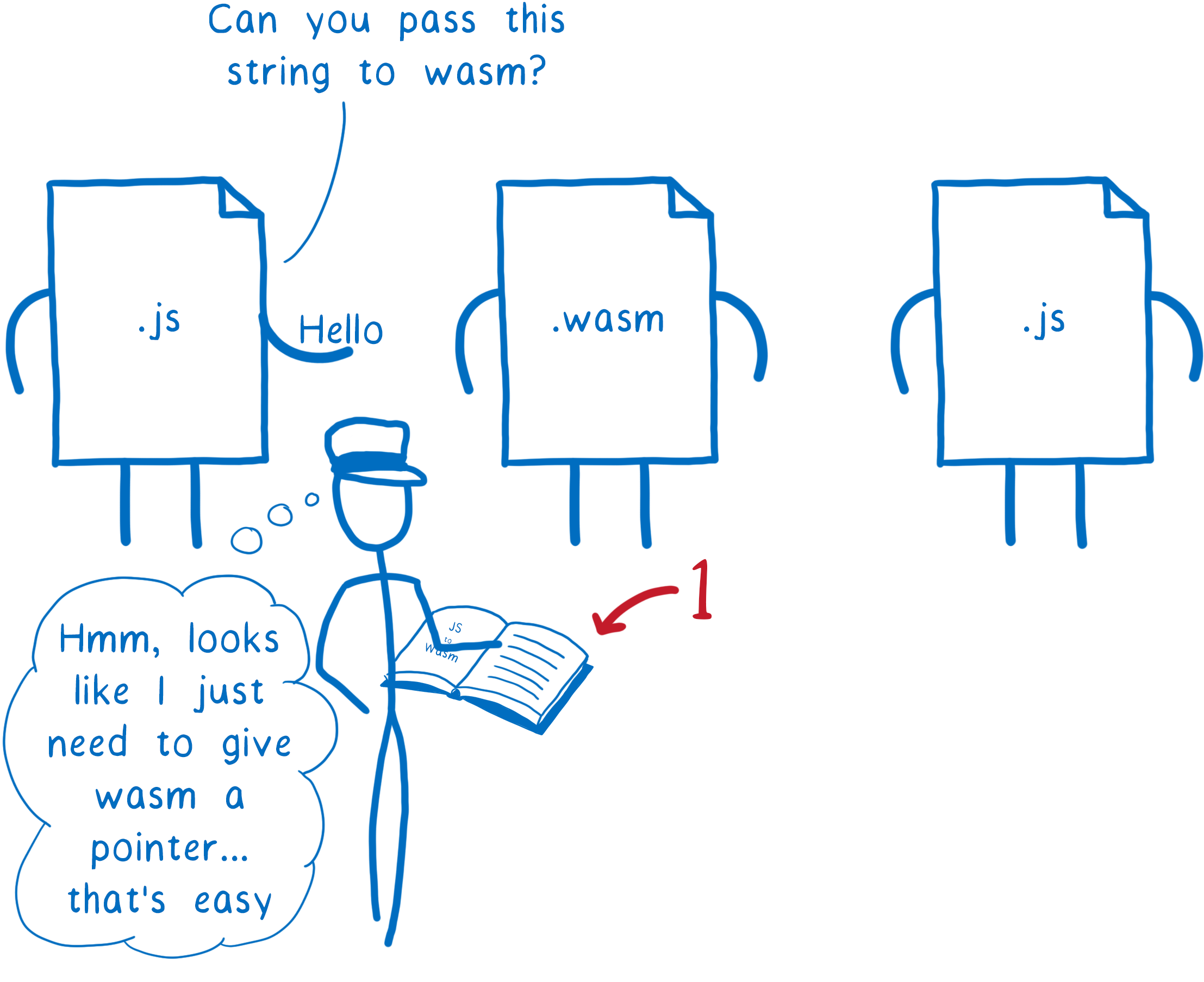
Si la chaîne de caractères pouvait directement être passée au module WebAssembly sans toutes ces transformations, ce serait bien plus simple.
WebAssembly ne pourrait pas manipuler cette valeur, il ne connaît pas ce type : on ne résout pas ce problème de compréhension.
Mais si on pouvait simplement passer la valeur au module WebAssembly comme un passe-plat, cela suffirait aux deux fonctions JavaScript, car elles savent quoi faire avec une valeur d’un tel type.
Il s’agit ici d’une raison de la proposition pour les types de référence WebAssembly. Cette proposition ajoute un nouveau type de base à WebAssembly intitulé anyref.
Avec une valeur anyref, un script JS fournirait au WebAssembly une référence objet (en fait un pointeur qui ne révèle pas l’adresse mémoire). Cette référence pointera vers l’objet sur le tas JS. Le module WebAssembly pourrait alors passer cette valeur à d’autres fonctions JS qui sauraient l’utiliser.
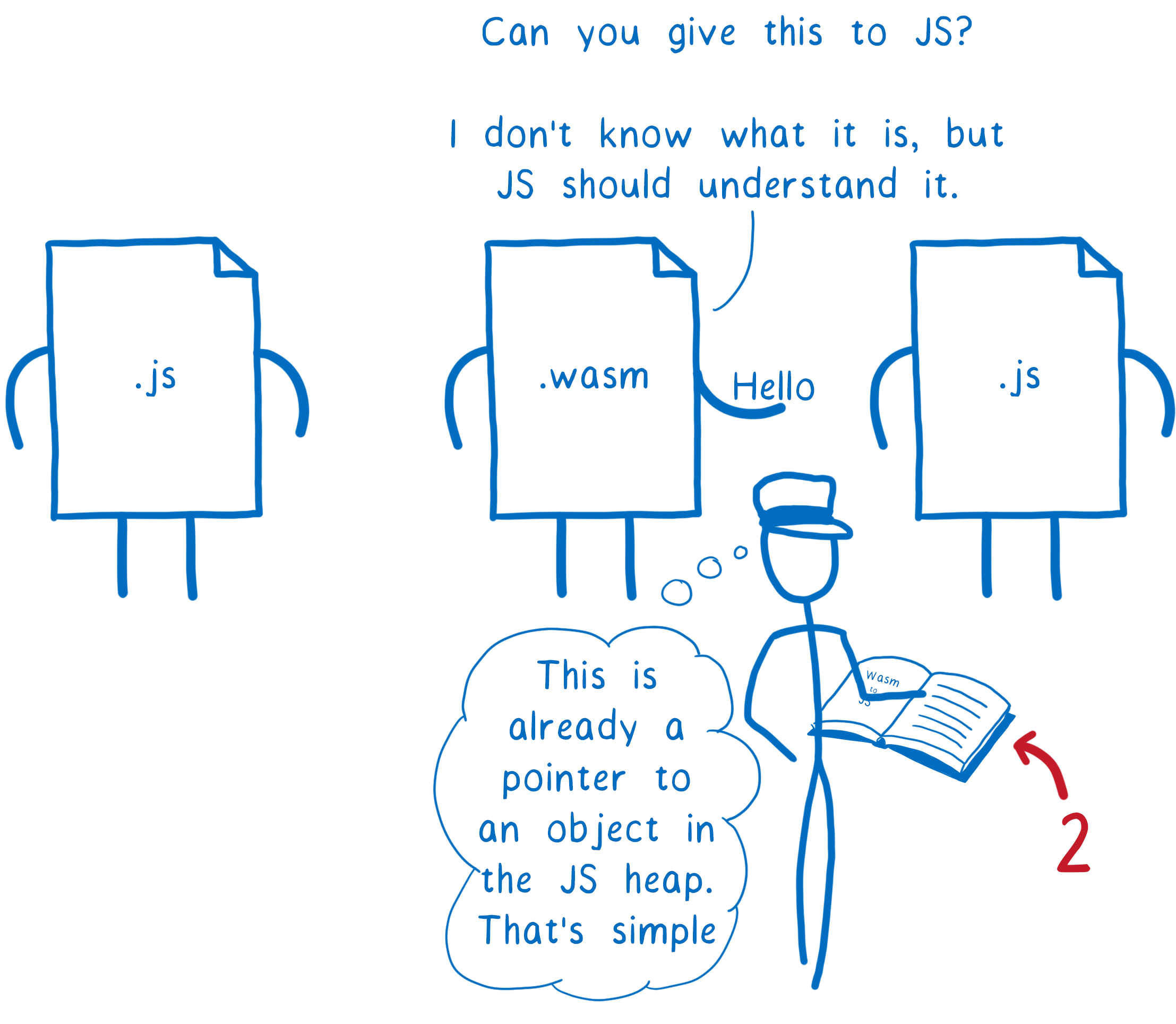
Cela résout un problème d’interopérabilité avec JavaScript, mais il en existe d’autres dans le navigateur.
Un navigateur possède un ensemble beaucoup plus large de types et WebAssembly doit être capable d’inter-opérer avec ces types si on veut que les performances soient décentes.
Discussion directe entre WebAssembly et le navigateur
JavaScript ne représente qu’une partie du navigateur. Ce dernier possède de nombreuses autres fonctions qu’on peut utiliser : les API Web.
Sous le capot, les fonctions de ces API Web sont généralement écrites en C++ ou en Rust. Ces deux langages stockent chacun à leur façon les objets en mémoires.
Les paramètres et valeurs de retour de ces API Web sont décrites par de nombreux types. Il sera fastidieux de décrire des conversions pour chacun de ces types. Pour simplifier les choses, il existe un standard pour la structure de ces types : Web IDL.
Lorsque vous utilisez ces fonctions, c’est généralement depuis du code JavaScript. Cela signifie que vous passez des valeurs exprimées sur des types JavaScript. Comment un type JavaScript se retrouve converti en type Web IDL ?
À l’instar des correspondances établies entre les types WebAssembly et les types JavaScript, il existe des correspondances entre les types JavaScript et Web IDL.
Là encore, on peut voir cela comme un autre manuel qui explique comment passer de Web IDL à JavaScript. Là aussi ces correspondances font partie intégrant du moteur du navigateur.
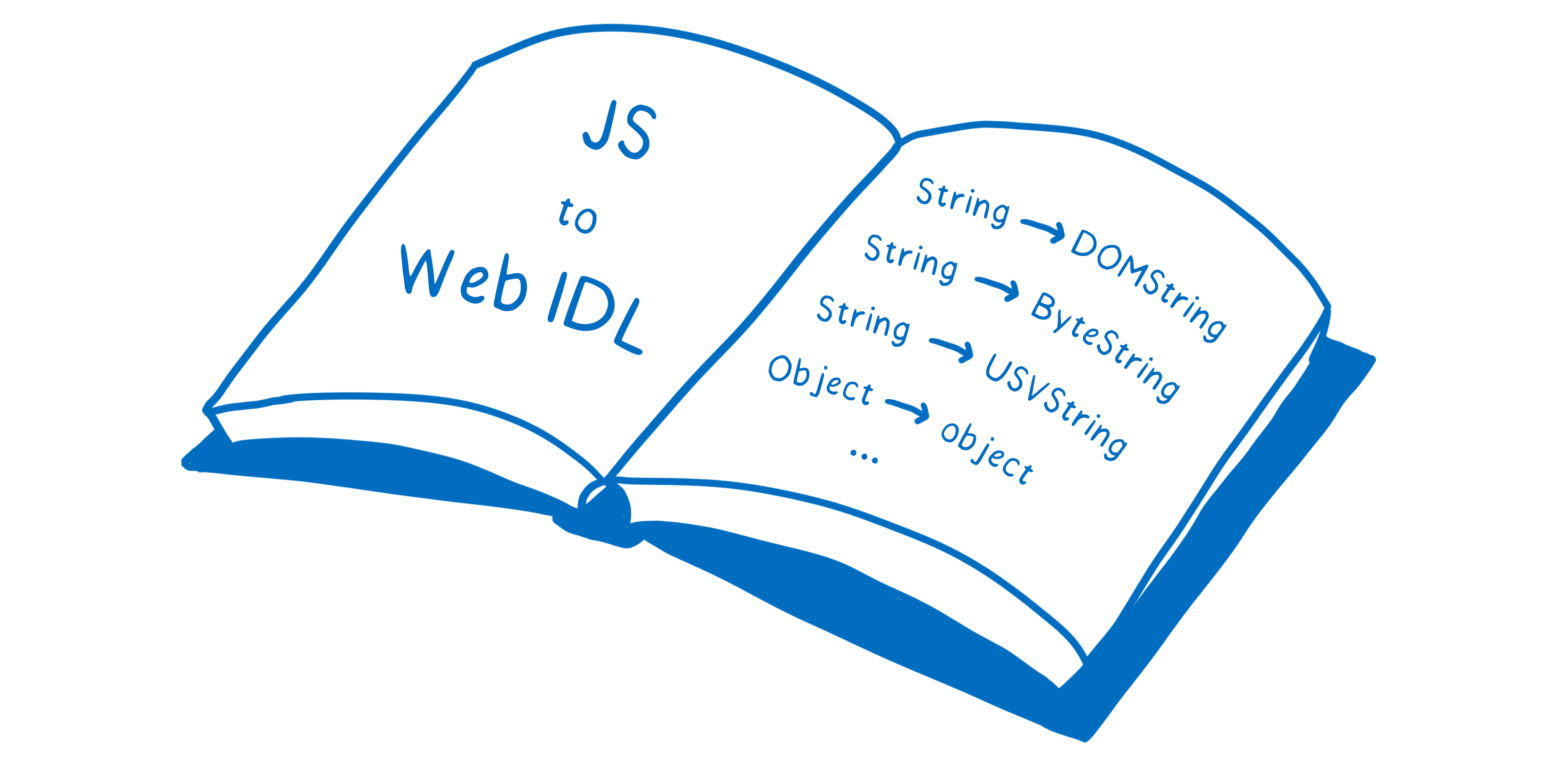
Pour la plupart des types, la correspondance entre JavaScript et Web IDL est assez simple. Ainsi, un type tel que DOMString est compatible avec le type JS String car les deux ont une correspondance directe.
Que se passe-t-il lorsqu’on essaie d’appeler une API Web depuis du code WebAssembly ? Il y a un problème.
À l’heure actuelle, il n’existe pas de correspondance entre les types WebAssembly et les types Web IDL. Cela signifie que même pour les types simples comme les nombres, l’appel doit passer par JavaScript.
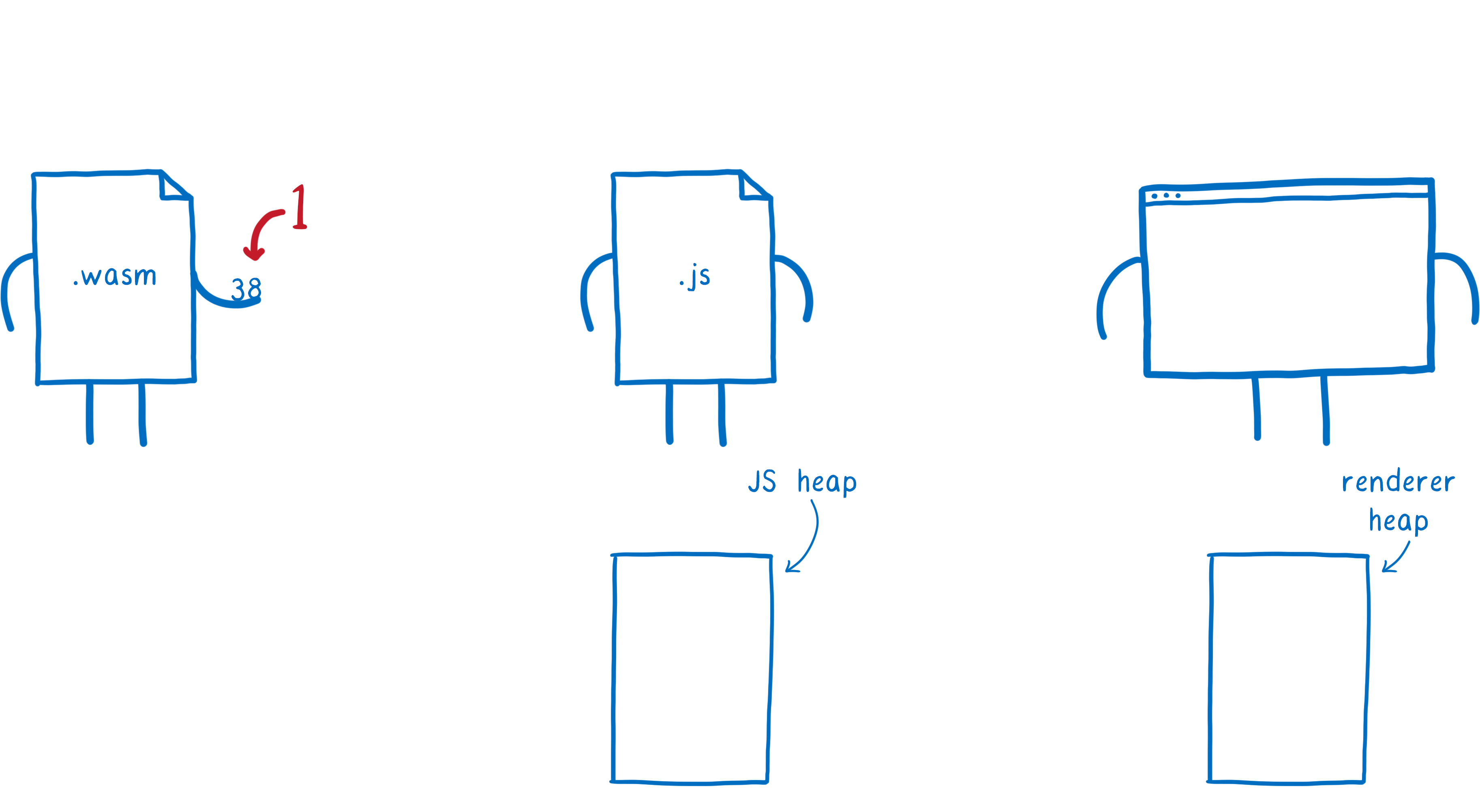
Voici ce qui se produit :
- WebAssembly passe la valeur au JavaScript
- Pour ce faire, le moteur convertit la valeur en un type JavaScript et la place sur le tas de la mémoire JavaScript
- La valeur JavaScript est ensuite passée à la fonction de la Web API. Ici, le moteur convertit la valeur JS en un type Web IDL et la place sur une autre zone mémoire, le tas du
renderer.
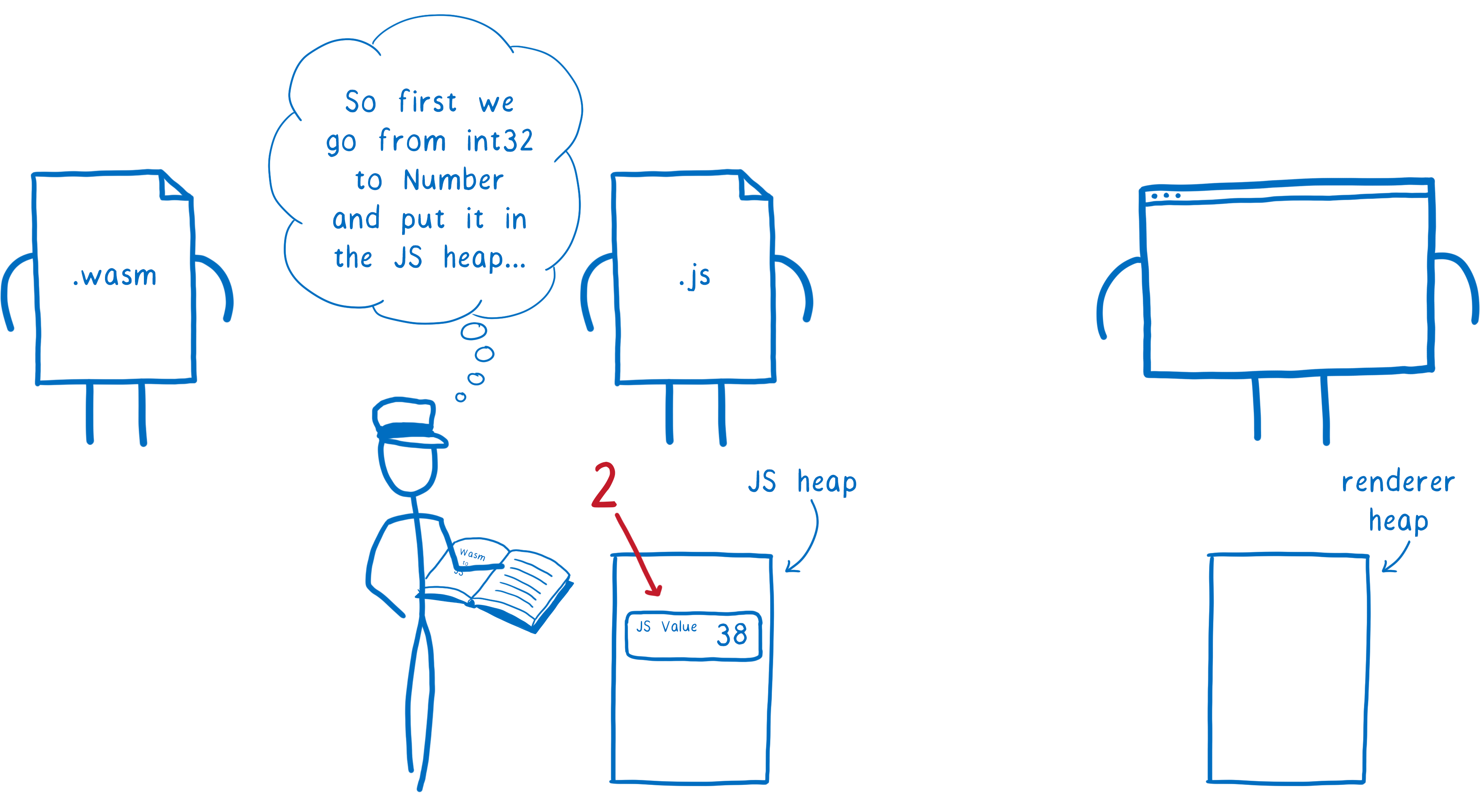

Ce n’est pas optimal : plus de tâches à effectuer et plus de mémoire consommée.
Une solution a priori évidente consisterait à créer des correspondances entre WebAssembly et Web IDL. Toutefois, ce n’est pas aussi trivial qu’il y paraît.
Pour les types Web IDL simples tels que booleanet unsigned long (un nombre), il existe des correspondances évidentes entre WebAssembly et Web IDL.
Mais une bonne partie des paramètres utilisées par les API Web ont des types complexes. Une API peut, par exemple, prendre un dictionnaire (comme un objet avec des propriétés) ou une série (un tableau) en entrée.
Pour créer une correspondance directe entre les types WebAssembly et les types Web IDL, il faudrait ajouter des types de plus haut niveau. C’est ce que nous faisons avec la proposition d’ajout d’un ramasse-miettes à WebAssembly. Grâce à ceci, les modules WebAssembly pourront créer des objets pour le ramasse-miettes tels que des structures et des tableaux qui pourront servir aux correspondances pour les types Web IDL.
Mais si la seule façon d’interagir avec les API Web consiste à utiliser les objets du ramasse-miettes, cela complique la tâche pour les langages tels que Rust et C++ qui n’utilisent pas les objets du ramasse-miettes en temps normal. À chaque interaction avec une API Web, il faudrait créer un objet du ramasse-miettes et copier les valeurs depuis la mémoire linéaire dans l’objet.
Le résultat ainsi obtenu est légèrement mieux que la situation actuelle avec le code de liaison JavaScript.
On ne souhaite pas avoir de code de liaison JavaScript pour construire les objets du ramasse-miettes : c’est un gaspillage de temps et de ressources. Réciproquement, on ne veut pas que le module WebAssembly construise ces objets pour les mêmes raisons.
On souhaite qu’appeler les API Web soit aussi simple pour les langages qui utilisent une mémoire linéaire (tels que Rust ou C++) que pour les langages qui utilisent un ramasse-miettes intégré. Il faut donc également une méthode pour créer une correspondance entre les objets en mémoire linéaire et les types Web IDL.
Mais il y a un hic. Chaque langage représente des choses en mémoire linéaire de façon différente. On ne peut pas choisir une de ces représentations spécifiquement, tous les autres langages en pâtiraient.

Bien que l’organisation mémoire soit différente, il y a certains concepts abstraits qui sont généralement partagés.
Ainsi, pour les chaînes de caractères, un langage possède souvent un pointeur vers le début de la chaîne de caractères et sa longueur. Si la chaîne de caractères possède une représentation plus complexe, il est généralement utile de convertir les chaînes vers ce format pour appeler des API externes.
De cette façon, on peut réduire la chaîne en un type que WebAssembly comprend : deux valeurs i32.

Là encore, un petit hic. WebAssembly est un langage fortement typé. Pour des raions de sécurité, le moteur vérifie que le code appelant passe des valeurs dont les types correspondent à ceux attendus par l’appelé.
Cela empêche les attaquants d’exploiter des incohérences de type pour détourner le moteur.
Si vous appelez une fonction qui utilise une chaîne de caractère et que vous tentez de lui passer un entier, le moteur vous criera dessus. Et ça tombe bien, c’est ce qu’il devrait faire.

Il nous faut donc une façon pour un module de dire au moteur quelque chose comme “Je sais que Document.createElement() prend une chaîne de caractères, mais je vais l’appeler et vous envoyer deux entiers. Prenez ces deux entiers pour créer un objet DOMString à partir des données en mémoire linéaire. Le premier entier sera l’adresse de départ de la chaîne de caractères et le second correspondra à sa longueur.”
C’est tout l’objectif de la proposition pour les types d’interfaçage Web IDL. On fournit à un module WebAssembly une façon d’indiquer une correspondance entre les types qu’il utilise et les types Web IDL.
Ces correspondances ne sont pas enregistrées en dur dans le moteur. C’est le module qui fournit un petit livret expliquant les correspondances qu’il utilise.

Le moteur a donc une méthode pour dire “pour cette fonction, la vérification des types pour les chaînes de caractères consistera à vérifier deux entiers”.
Le couplage entre le module et ce livret d’explication est aussi utile pour une autre raison.
Parfois, un module qui stocke normalement ses chaînes en mémoire linéaire pourra vouloir utilise une anyref ou un type du ramasse-miettes pour un cas spécifique. C’est le cas notamment pour un module qui passe un objet qu’il a obtenu d’une fonction JavaScript (un nœud du DOM par exemple) vers une API Web.
Ainsi, un module doit pouvoir choisir au cas par cas entre les fonctions (voire entre les arguments) la façon dont la correspondance de type est gérée. La correspondance étant fournie par le module, ce dernier peut décrire une correspondance sur-mesure.

Comment faire pour générer ce livret ?
Le compilateur prend en charge cette opération. Il ajoute une section spécifique au module WebAssembly. Pour la plupart des chaînes de compilation des différents langages, le développeur n’aura pas un grand travail supplémentaire.
Prenons un exemple avec la chaîne de compilation Rust et comment celle-ci gère le passage d’une chaîne de caractères à la fonction alert.
#[wasm_bindgen]
extern "C" {
fn alert(s: &str);
}
Le développeur doit juste indiquer au compilateur d’ajouter cette fonction au livret avec l’annotation #[wasm_bindgen]. Par défaut, le compilateur considèrera qu’il s’agit d’une chaîne de caractères représentée en mémoire linéaire et ajoutera la bonne correspondance. Si on avait souhaité la gérer différemment (comme un anyref par exemple), on aurait écrit une autre annotation à destination du compilateur.
Grâce à ça, on peut enlever le code JavaScript intermédiaire pour la liaison. Le passage de valeur entre WebAssembly et les API Web est plus rapide. De plus, cela fait moins de JavaScript à distribuer.
Au passage, aucun compromis n’a été effectué quant aux langages pris en charges. On peut utiliser n’importe quel langage qui compile vers WebAssembly. Tous ces langages peuvent définir leur correspondance vers les types Web IDL, peu importe qu’ils utilisent une mémoire linéaire, des objets de ramasse-miettes ou les deux.
En prenant un peu de recul sur cette solution, on peut voir qu’elle résout un bien plus grand problème.
WebAssembly : un langage pour tous leur parler
Revenons à la promesse que nous évoquions au début de ce billet.
Existe-t-il une méthode réaliste afin que WebAssembly puisse parler à ces différents systèmes quels que soient les types qu’ils utilisent ?
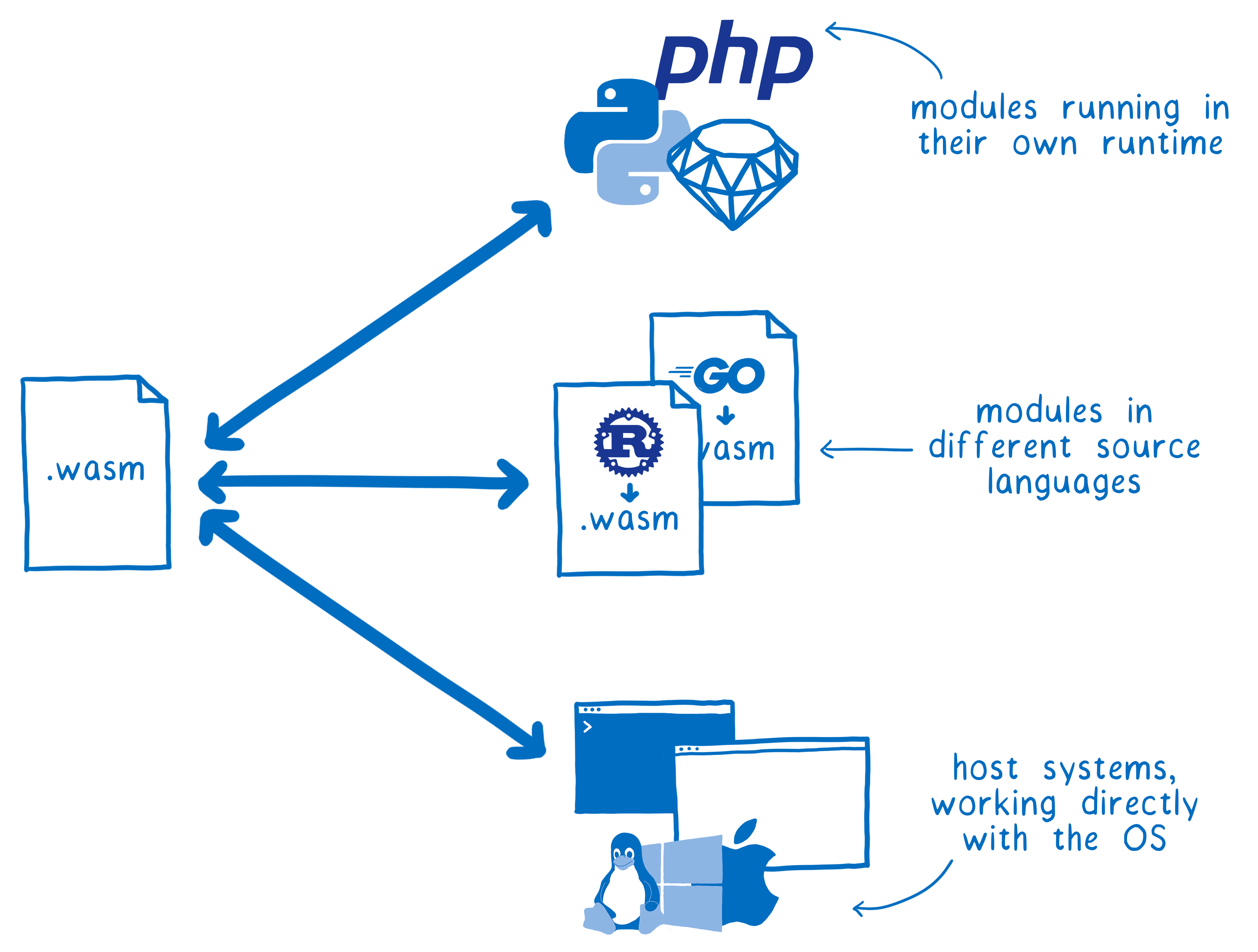
Quelles sont les options ?
On pourrait essayer de créer des correspondances inscrites en dur dans le moteur (à la façon de ce qui est fait entre WebAssembly et JavaScript d’une part et entre JavaScript et WebIDL d’autre part).
Mais pour ce faire, il faudrait une correspondance spécifique par langage. Le moteur aurait à prendre en charge chacune de ces correspondances explicitement et les mettre à jour à chaque changement de chaque langage. Bref, c’est la pagaille.
C’est de cette façon que furent conçus les premiers compilateurs. Il existait une trajectoire différente entre chaque langage source et chaque langage machine. Nous en parlions plus en détails dans un des premiers billets sur WebAssembly.

On ne veut pas avoir quelque chose d’aussi compliqué. On veut que chaque langage puisse parler à chaque plateforme. Et en même temps, on veut que cette approche soit extensible.
Il nous faut donc une autre approche et on peut s’inspirer des architectures des compilateurs modernes. Pour ceux-ci, il y a une division entre le front-end et le back-end. La partie front-end porte sur le langage source traduit en une représentation intermédiaire abstraite. La partie back-end part de cette représentation intermédiaire jusqu’au code machine cible.
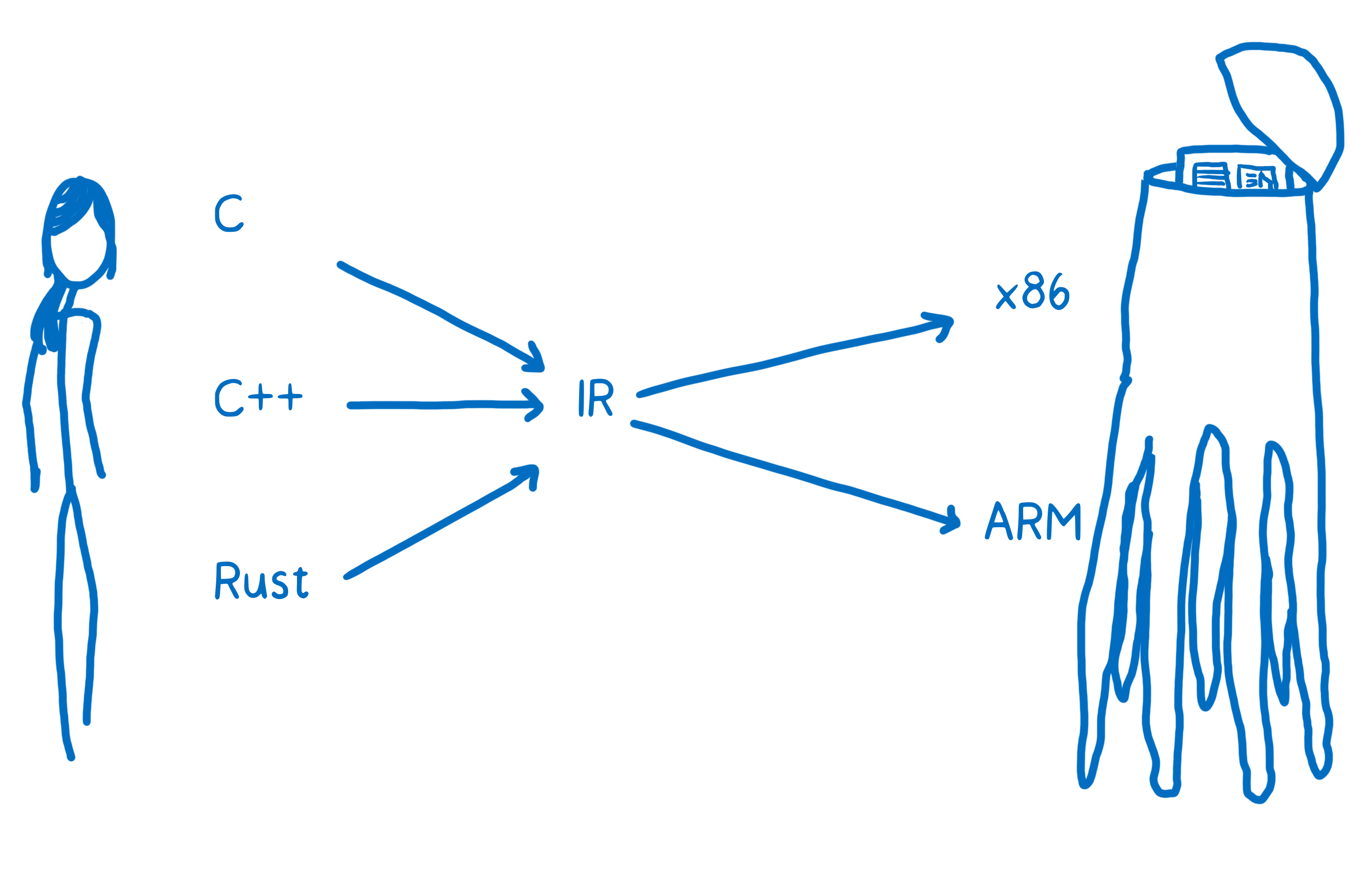
C’est de cette méthode dont s’inspirent les types Web IDL. Quand on le regarde d’un autre angle, Web IDL ressemble un peu à une représentation intermédiaire.
Ceci étant posé, Web IDL est assez spécifique au Web. Et il existe de nombreux cas d’usage pour WebAssembly en dehors du Web. Web IDL n’est donc pas la représentation intermédiaire qu’il faut.
Malgré cela, pouvons-nous nous inspirer de Web IDL et créer un nouvel ensemble de types abstraits ?
C’est ainsi qu’on arrive à la proposition pour les types d’interfaçage WebAssembly.

Ces types ne sont pas des types concrets. Ils ne ressemblent pas aux types qu’on trouve aujourd’hui dans WebAssembly comme int32 ou float64. On ne peut pas les manipuler avec des opérations en WebAssembly.
On n’ajoutera par exemple pas de méthode de concaténation de chaînes de caractères dans WebAssembly. Toutes les opérations seront effectuées sur les types concrets à chaque extrêmité.
La clef de voûte de ce fonctionnement est la copie des valeurs d’un côté à l’autre. Plutôt que de partager une représentation commune, les deux parties utilisent les types d’interfaçage pour copier les valeurs.
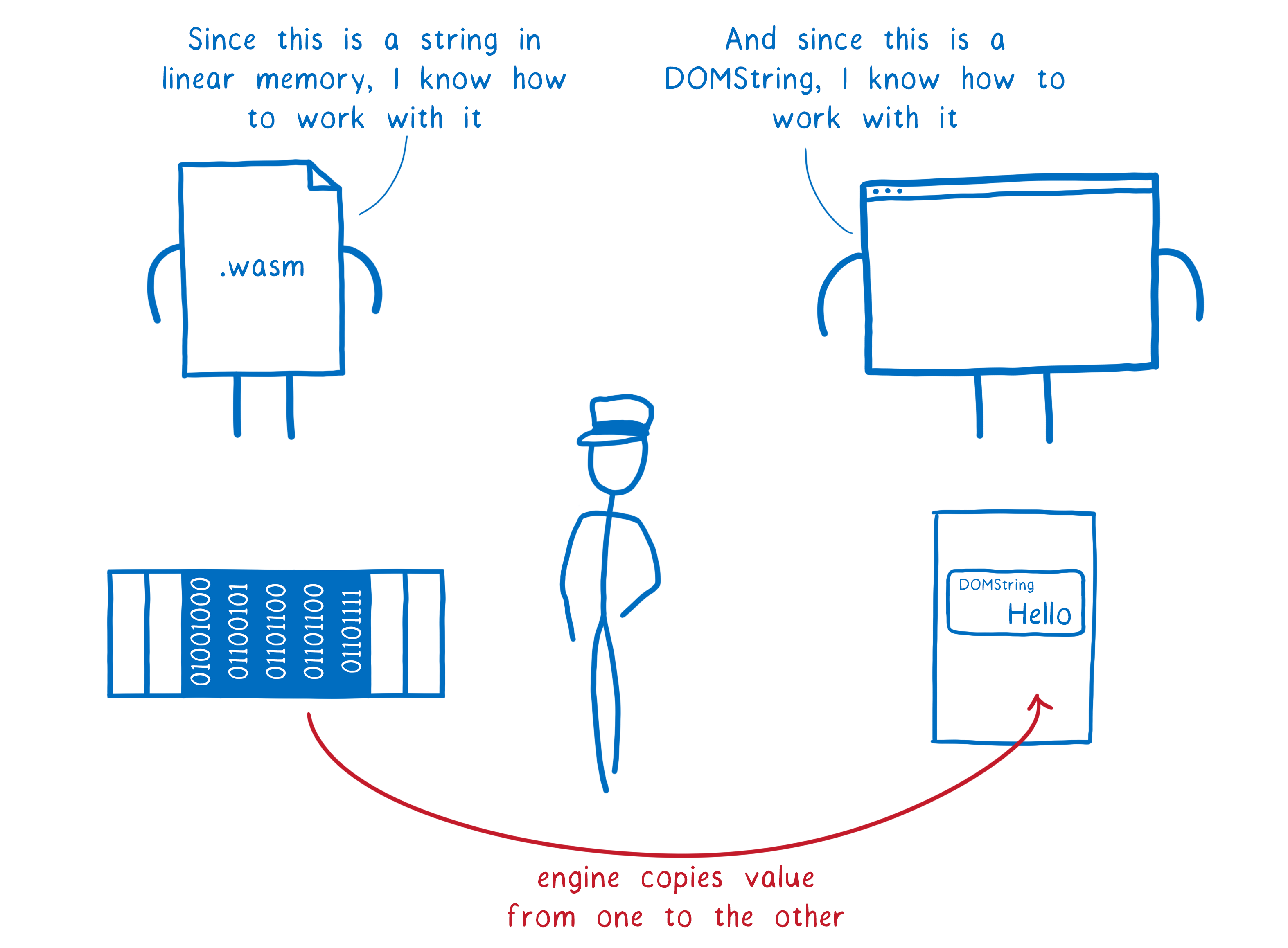
Il existe un point qui pourrait constituer une exception à cette règle : les nouvelles valeurs de référence (telles que anyref) que nous avons mentionnées plus haut. Dans ce cas, c’est le pointeur vers l’objet qui est copié entre les deux côtés. Les deux pointeurs pointent donc vers la même chose. En théorie, cela peut vouloir dire qu’ils ont besoin de partager une représentation.
Dans les cas où la référence ne fait que “traverser” un module WebAssembly (comme l’exemple que nous avons vu avec anyref), les deux interlocuteurs n’ont pas à partager une représentation. Le module n’est pas supposé comprendre ce type mais simplement le passer entre les fonctions.
Il existe cependant des scénarios où on souhaite que les interlocuteurs partagent une représentation. Par exemple, la proposition pour le ramasse-miettes ajoute une méthode pour créer des défintions de type afin que les deux parties puissent partager des représentations. Dans ces cas, le choix de la représentation et de ce qu’il faut partager est effectué par les développeurs qui conçoivent l’API.
Cette approche rend le dialogue beaucoup plus simple entre un module WebAssembly et de nombreux langages.
Dans certains cas (comme celui du navigateur), la correspondance entre les types d’interfaçage et les types du système sous-jacent sera inscrite en dur.
Ainsi, une partie des correspondances est construite à la compilation tandis que l’autre est fourni au moteur lors du chargement du contenu.
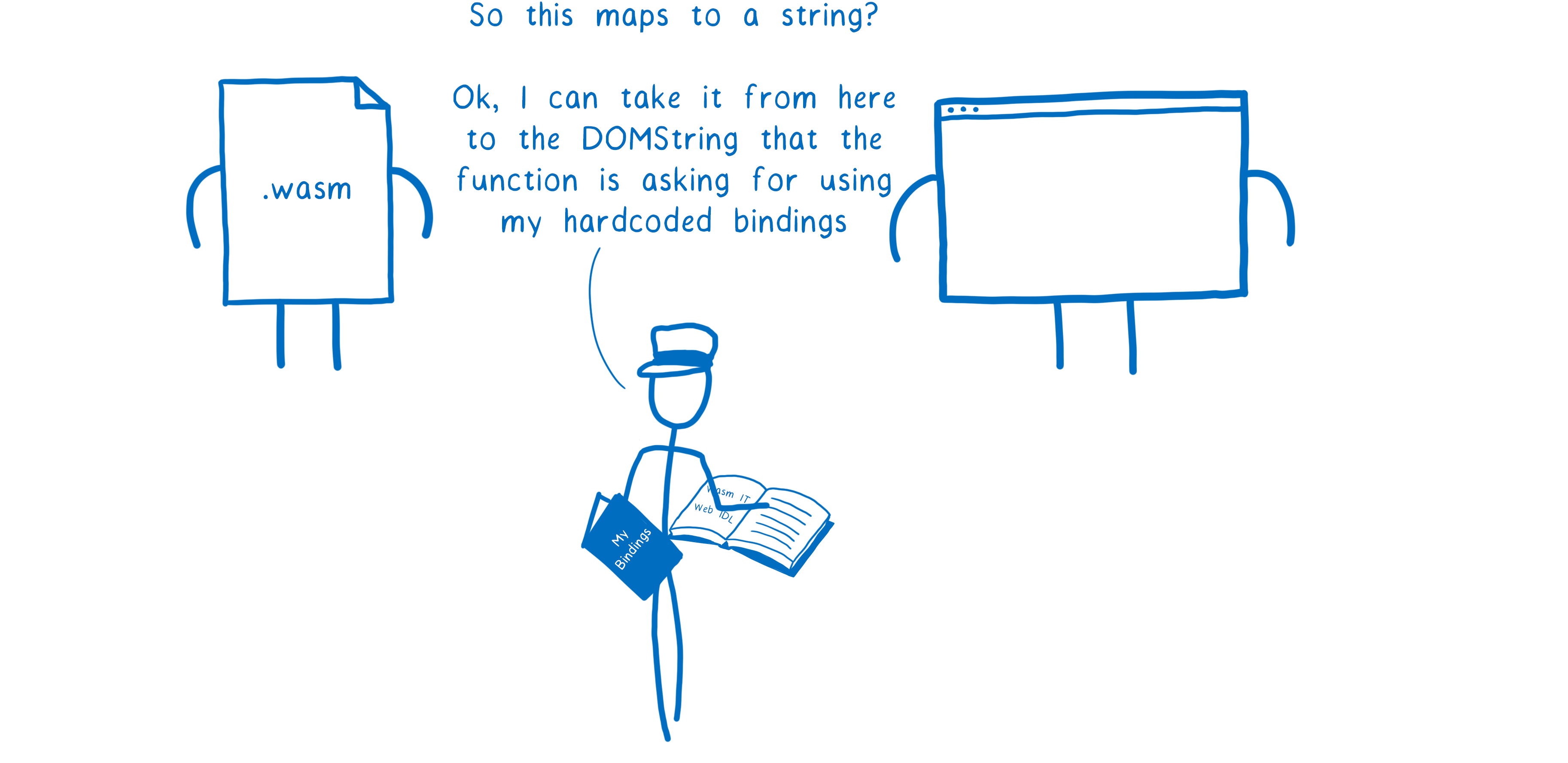
Dans les autres cas, par exemple quand deux modules WebAssembly échangent entre eux, les deux envoient leurs livrets d’instruction qui décrivent chacun leurs correspondances entre les types de fonction et les types abstraits.

Ce n’est pas la seule chose nécessaire pour que des modules écrits avec différents langages sources se parlent (nous reviendrons sur ce sujet) mais c’est un grand pas dans cette direction.
À quoi ressemblent ces types d’interfaçage ?
Avant d’aller plus loin dans les détails, rappelons que cette proposition est toujours en cours de développement. Le résultat final pourrait s’avérer complètement différent.
De plus, tout est géré par le compilateur. Même après que cette proposition ait été finalisée, vous aurez uniquement à connaître les annotations attendues par la chaîne de compilation pour les mettre dans votre code (à la façon de ce que nous avons fait avec wasm-bindgen plus haut). Il n’est pas vraiment nécessaire de savoir comment ça fonctionne sous le capot.
Vu que les détails exposés par la proposition sont assez clairs, profitons-en pour voir comment tout cela s’articule.
Le problème à résoudre
Le problème consiste à traduire des valeurs entre différents types lorsqu’un module dialogue avec un autre module (ou avec un hôte comme le navigateur).
On a quatre endroits où on peut avoir besoin de traduire :
- Pour les fonctions exportées
- la réception de paramètres depuis l’appelant
- l’envoi des valeurs de retour vers l’appelant
- Pour les fonctions importées
- le passage des paramètres à la fonction
- la réception des valeurs de retour
On peut voir chacun de ces cas comme un mouvement sur deux directions :
- La montée pour les valeurs qui quittent le module. Elles passent d’un type concret à un type d’interfaçage.
- La descente pour les valeurs qui arrivent dans le module. Elles passent d’un type d’interfaçage à un type concret.
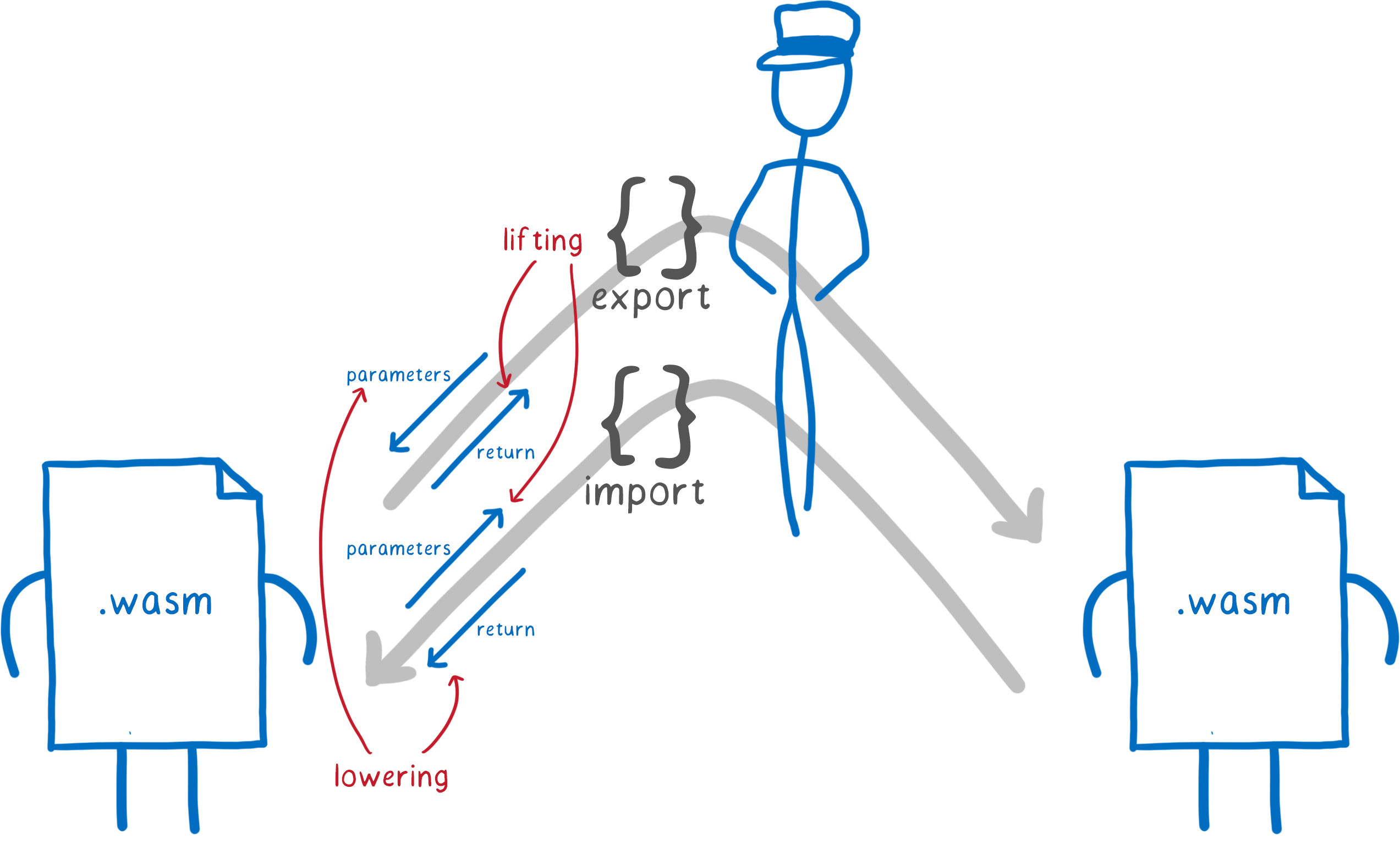
Indiquer au moteur les transformations à effectuer entre les types concrets et les types d’interfaçage
Il faut donc une méthode pour indiquer au moteur les transformations à appliquer aux paramètres et aux valeurs de retour d’une fonction. Comment faire ?
En définissant un adaptateur d’interface.
Prenons l’exemple d’un module Rust compilé en WebAssembly. Ce module exporte une fonction greeting_ qui peut être appelée sans paramètre et qui renvoie un message de salutation.
Voici ce qu’on aurait actuellement (avec le format textuel WebAssembly).

Pour le moment, la fonction renvoie deux entiers.
Mais on voudrait qu’elle renvoie une valeur pour le type d’interfaçage string. On ajoute donc quelque chose qu’on appelle un adaptateur d’interface.
Si un moteur prend en charge les types d’interfaçage, lorsqu’il verra un adaptateur d’interface, il enveloppera le module dans cette interface.

Le module n’exporte plus la fonction greeting_ mais la fonction greeting qui enveloppe l’originale. La nouvelle fonction greeting renvoie une chaîne de caractères et plus deux entiers.
On obtient une compabilité ascendante, car les moteurs qui ne comprennent pas les types d’interface exporteront la fonction originale greeting_ (celle qui renvoie deux entiers).
Comment l’adaptateur d’interface explique au moteur comment transformer deux entiers en une chaîne ?
Il utilise une séquence d’instructions d’adaptateur.

Les instructions d’adaptateur présentées dans cette image sont deux exemples d’un ensemble d’instructions qui sont définies dans cette proposition.
Voici ce que font les instructions précédentes :
- Utiliser l’instruction d’adaptateur
call-exportafin d’appeler la méthode originalegreeting_. C’est la fonction exportée par le module original qui renvoie deux nombres. Ces deux nombres sont placés sur la pile. - Utiliser l’instruction d’adaptateur
memory-to-stringqui convertit les nombres en une séquence d’octets qui composent la chaînes de caractères. On doit ici préciser"mem"à la suite car un module WebAssembly pourrait demain avoir plusieurs espaces mémoire. On indique ainsi au moteur l’espace mémoire à consulter. Le moteur prend alors les deux nombres sur le dessus de la pile (qui correspondent au pointeur et à la longueur) et les utilise afin de déterminer les octets à utiliser.
Cela ressemble un peu à un langage de programmation, mais il n’y a pas de contrôle du flux d’instructions ici (pas de boucles ou d’instructions conditionnelles). Il s’agit d’un langage déclaratif qui nous permet de fournir des instructions au moteur.
À quoi cela ressemblerait-il si notre fonction prenait une chaîne en paramètre (le nom de la personne à saluer par exemple).
Eh bien c’est assez proche. On modifie l’interface de la fonction d’adaptation afin d’ajouter le paramètre et on ajoute ensuite deux instructions d’adaptateur.

Voilà ce que font ces nouvelles instructions :
- Utiliser l’instruction
arg.getafin d’obtenir une référence à l’objet qu’est la chaîne de caractères qu’on place sur la pile. - Utiliser l’instruction
string-to-memoryafin de récupérer les octets de cet objet pour les placer en mémoire linéaire. Là encore, on précise l’espace mémoire dans lequel inscrire ces octets. On précise également comment allouer ces octets. Pour cela on fournit une fonction d’allocation (qui pourrait être un export fourni par le module).
Si vous souhaitez en savoir plus sur ce fonctionnement, vous pouvez consulter cette explication qui va plus en détails.
Envoyer les instructions au moteur
Comment envoyer tout cela au moteur ?
Ces annotations sont ajoutées au fichier binaire dans une section spécifique (custom).

Si un moteur sait exploiter les types d’interfaçage, il pourra utiliser cette section. Sinon, il pourra l’ignorer et vous pourrez utiliser une prothèse (polyfill) afin de lire la section et écrire du code de liaison.
Quelles différences avec CORBA, Protocol buffers, etc. ?
Il existe actuellement d’autres standards qui semblent résoudre ce même problème dont CORBA, Protocol buffers, Cap’n Proto.
En quoi ceux-ci sont différents ? Ils résolvent un problème beaucoup plus difficile.
Ils ont été conçus afin de pouvoir interagir avec un système avec lequel on ne partage pas de mémoire (soit parce qu’il s’agit d’un autre processus ou d’une toute autre machine sur le réseau).
Cela signifie qu’il faut pouvoir envoyer cette représentation intermédiaire par-delà cette frontière.
Ces standards visent à définir un format de sérialisation qui puisse efficacement voyager sur cette frontière. C’est là un des aspects essentiels de ces standards.
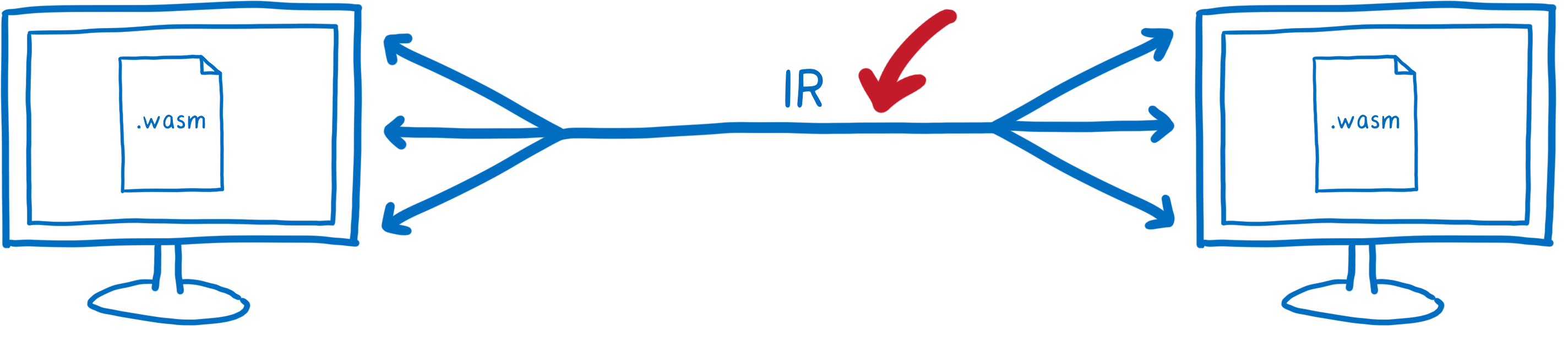
Bien que le problème semble similaire, il s’agit en fait de l’exact inverse.
Avec les types d’interfaçage, la représentation intermédiaire (l’« IR ») ne quitte jamais le moteur. Elle n’est même pas visible pour les modules.
Les modules ne voient que ce le moteur leur fournit à la fin (ce qui a été copié sur leur mémoire linéaire ou fourni comme référence). Il n’est pas nécessaire d’indiquer au moteur l’organisation de ces types, car elle n’est pas définie.
Ce qui est défini, en revanche, est la façon de parler au moteur. Il s’agit du langage déclaratif utilisé pour écrire ce livret envoyé au moteur.
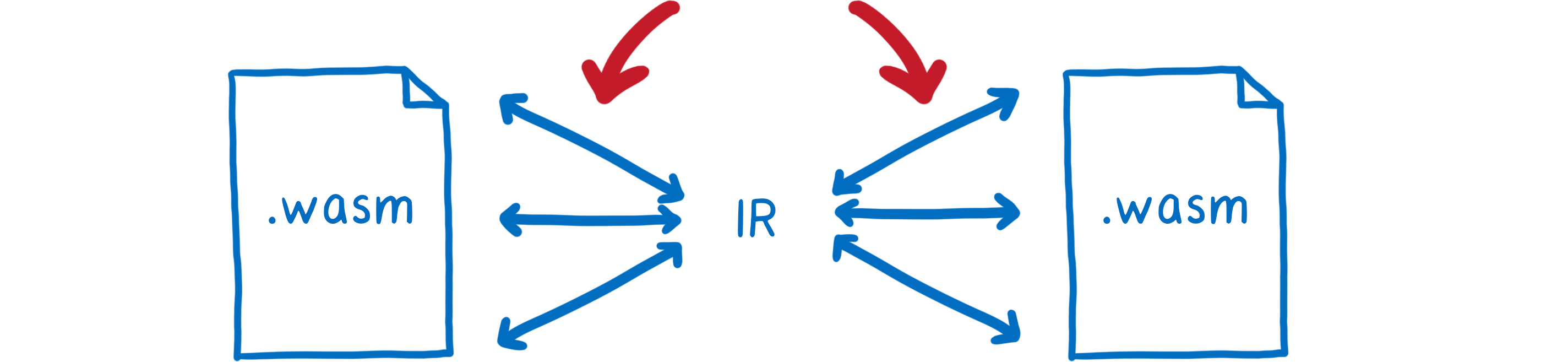
De cet aspect déclaratif découle un effet de bord appréciable : le moteur peut détecter lorsqu’une « traduction » entre types est superflue. Ainsi si les deux modules qui discutent utilisent le même type, le moteur évitera cette double transformation.

Comment utiliser tout ça aujourd’hui ?
Comme nous l’avons indiqué plus haut, il s’agit d’une proposition au stade encore expérimental. Certaines choses risquent de changer rapidement et il serait risqué d’utiliser tout ça en production.
Ceci étant posé, si vous souhaitez manipuler tout ça, nous avons implémenté le nécessaire sur l’ensemble de la chaîne de compilation : de la production de code à la consommation :
- La chaîne de compilation Rust
wasm-bindgen- L’environnement d’exécution WebAssembly Wasmtime
Comme nous maintenons ces outils et que nous travaillons sur le standard, nous pouvons maintenir le nécessaire pendant le développement du standard.
Bien que tout ça continue d’évoluer, nous nous assurons de synchroniser ces évolutions avec ces outils. Ainsi, tant que vous utilisez des versions à jour de ces outils, vous ne devriez pas rencontrer trop de problèmes.
Voici donc les nombreuses façons dont vous pouvez utiliser tout ça aujourd’hui. Pour une version à jour, vous pouvez consulter ce dépôt de démonstrations.
Remerciements
- Merci à l’équipe qui a assemblé toutes ces pièces pour tous ces langages et tous ces environnements d’exécution : Alex Crichton, Yury Delendik, Nick Fitzgerald, Dan Gohman et Till Schneidereit
- Merci aux porteurs de cette proposition et à leurs collègues pour leur travail dessus : Luke Wagner, Francis McCabe, Jacob Gravelle, Alex Crichton et Nick Fitzgerald
- Merci à mes merveilleux collègues : Luke Wagner et Till Schneidereit pour leurs retours et contributions inestimables à cet article.
À propos de Lin Clark
Lin travaille au sein de l’équipe ‘Advanced Development’ de Mozilla et notamment sur Rust et WebAssembly.
