Si les débuts de JavaScript sont marqués par une lenteur, il est devenu sensiblement plus rapide grâce à un truc appelé JIT. OK, mais comment fonctionne ce fameux JIT ?
Comment JavaScript est exécuté par les navigateurs
Quand le développeur que vous êtes ajoute du JavaScript dans une page web, vous avez un objectif et un problème. Objectif : vous voulez dire à l’ordinateur ce qu’il doit faire. Problème : l’ordinateur et vous ne parlez pas du tout le même langage.
Vous, vous parlez un langage humain ; l’ordinateur, lui, parle un langage de machine. Même si vous pensez que JavaScript ou n’importe quel autre langage de programmation de haut niveau n’est pas un langage humain, ne vous y trompez pas, c’est bien le cas. Ils ont été créés pour se conformer au mode de pensée des humains, pas des machines.
Ainsi, le travail du moteur JavaScript consiste à prendre votre langage humain et le convertir en quelque chose qu’une machine peut comprendre. Je vois ça comme dans le film Premier Contact, dans lequel des humains et des extraterrestres essaient de se parler.

Dans ce film, les humains et les extraterrestres ne font pas de traduction mot à mot. Les deux groupes ont différentes façons de penser le monde. Eh bien figurez-vous que c’est la même chose entre les humains et les machines (on verra ça en détail dans le prochain article).
Donc, comment se fait cette traduction?
Dans le monde de la programmation il existe généralement deux façons de faire une traduction vers du langage machine : en utilisant un interpréteur ou en utilisant un compilateur.
Avec un interpréteur, cette traduction se fait en temps réel, quasiment ligne par ligne.
D’un autre côté, un compilateur ne fait pas une traduction en temps réel, il travaille en amont pour créer sa traduction et la retranscrire intégralement. Avec un interpréteur, cette traduction se fait en temps réel, quasiment ligne par ligne.

Chacune de ces deux façons de procéder présente des avantages et des inconvénients.
Le pour et le contre des interpréteurs
Les interpréteurs sont rapides à l’allumage. Ils n’ont pas franchir toutes les étapes de compilation avant de pouvoir exécuter quoi que ce soit. Ils commencent la traduction de la première ligne et l’exécutent immédiatement.
Grâce à ça, un interpréteur semble naturellement être un bon choix pour exécuter quelque chose comme JavaScript. C’est important pour un développeur web de pouvoir commencer à exécuter son code aussi vite que possible. C’est pour cette raison les navigateurs ont utilisé des interpréteurs pour exécuter JavaScript à leur début.
Le problème avec les interpréteurs survient quand vous voulez exécuter le même code plus d’une fois. Typiquement quand vous utilisez une boucle. Dans ce cas, l’interpréteur doit faire la même traduction encore et encore.
Le pour et le contre des compilateurs
Un compilateur choisit les compromis opposés.
Il a besoin d’un peu plus de temps au démarrage parce qu’il doit passer par toutes les étapes de compilation avant de pouvoir faire quoi que ce soit. Cependant exécuter le code d’une boucle est bien plus rapide puisqu’il n’est plus nécessaire de refaire le travail de traduction à chaque passage dans la boucle.
Une autre différence tient à ce que les compilateurs ont plus de temps pour observer le code et le modifier pour qu’il puisse s’exécuter plus rapidement. Ces modifications ne sont ni plus ni moins que des optimisations. Comme les interpréteurs font le travail de traduction en même temps qu’ils exécutent le code, ils ne peuvent pas se permettre de prendre beaucoup de temps pour faire des optimisations.
Les compilateurs « juste à temps » : le meilleur des deux mondes
Afin de passer outre l’inefficacité des interpréteurs — devoir traduire le même code encore et encore — les navigateurs ont commencé à leur adjoindre des compilateurs.
Chaque navigateur le fait de manière légèrement différente, cependant l’idée de base reste la même. On ajoute une nouvelle pièce au moteur JavaScript : un profileur de code. Ce profileur observe le code pendant qu’il s’exécute et prend des notes sur le nombre de fois qu’est exécuté un bout de code et sur les types utilisés.
Au début le profileur fait tout passer dans l’interpréteur.
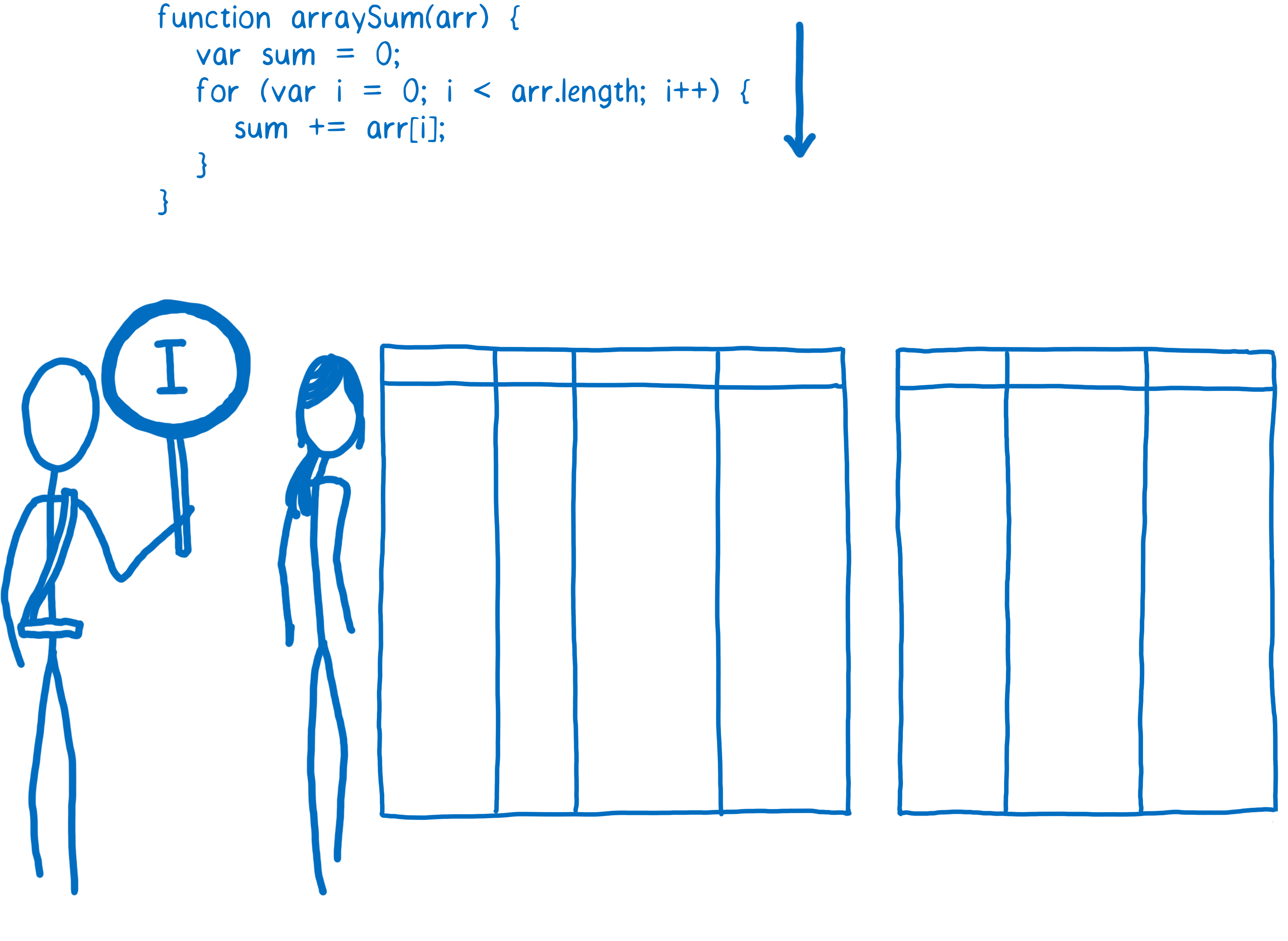
Si les mêmes lignes de code sont exécutées quelques fois, ce bout de code est considéré comme « tiède ». S’il est exécuté très souvent il est considéré comme « chaud ».
Compilateur de base
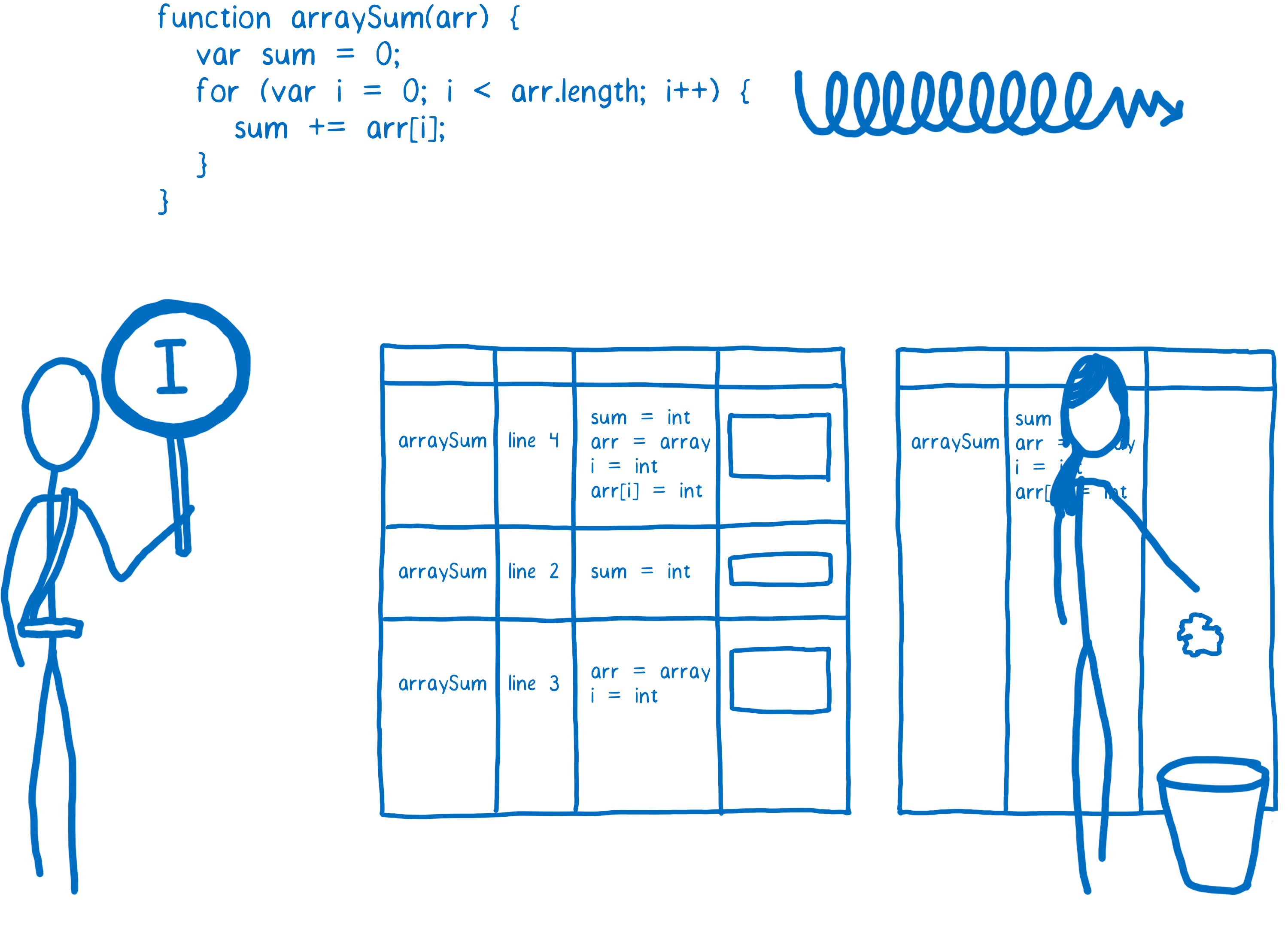
Quand une fonction devient tiède, le JIT va l’envoyer au compilateur et va stocker le résultat de la compilation.
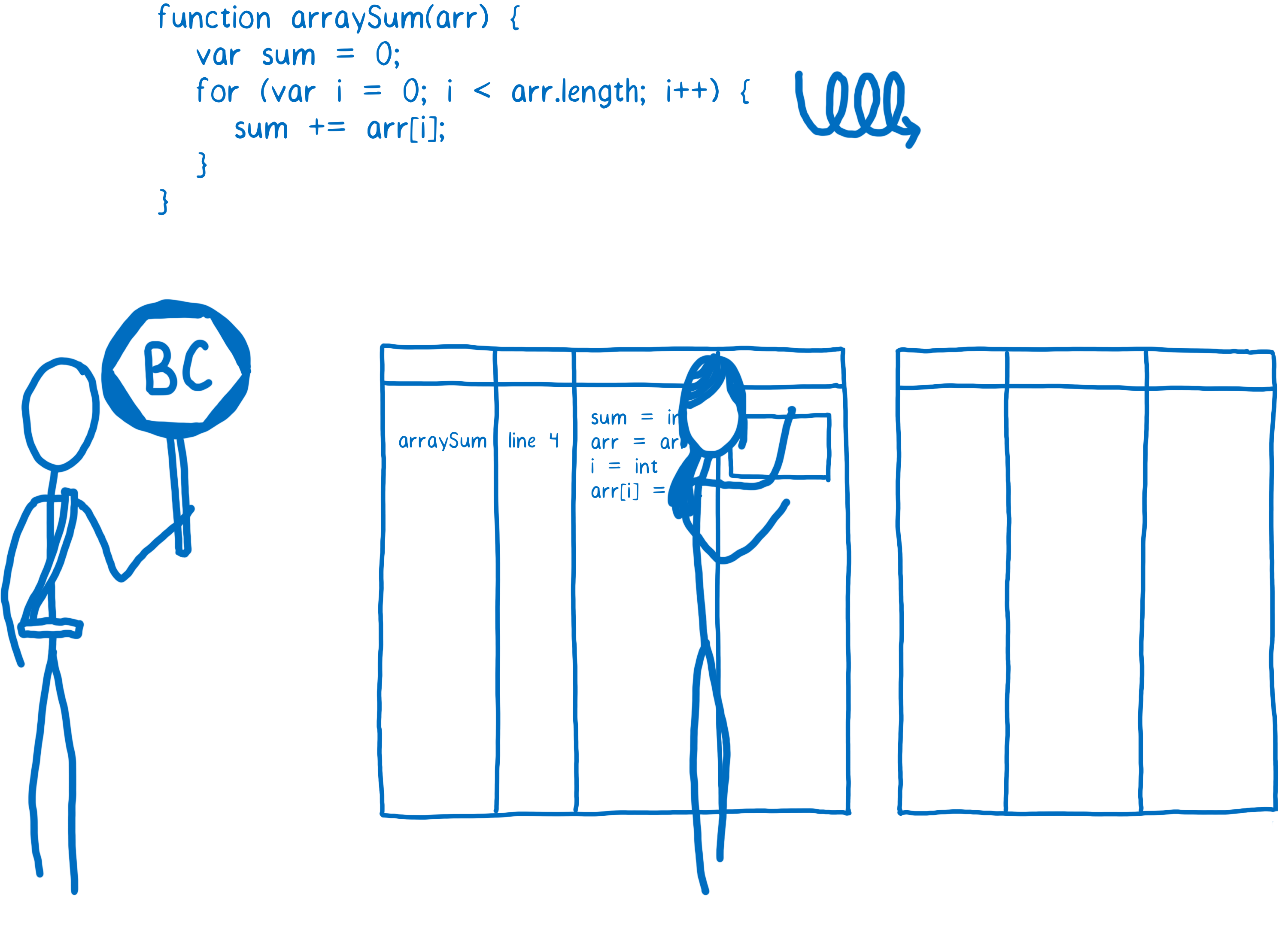
Chaque ligne de code est compilée sous forme d’un « extrait » (NDT stub en anglais). Les extraits sont indexés par numéro de ligne et par type de variable (j’expliquerai pourquoi c’est important plus tard). Si le profileur remarque que le même code avec les mêmes types de variables est exécuté à nouveau il utilisera simplement l’extrait compilé.
Ça aide à accélérer les choses. Mais comme je le disais, un compilateur peut faire bien plus. Il peut prendre le temps de comprendre la façon la plus efficace de faire certaines choses… de faire des optimisations. Le compilateur de base va faire quelques-unes de ces optimisations (j’en donne un exemple ci-après). Cela ne doit pas prendre trop de temps, car il ne veut pas bloquer l’exécution trop longtemps.
Cependant, si ce code est vraiment chaud — s’il est exécuté vraiment très souvent — alors ça vaut la peine de prendre le temps de faire davantage d’optimisations.
Compilateur optimisant
Quand un bout de code est vraiment chaud, le profileur va demander une compilation optimisée. Cela va créer une autre version encore plus rapide de ce code qui sera lui aussi stocké.
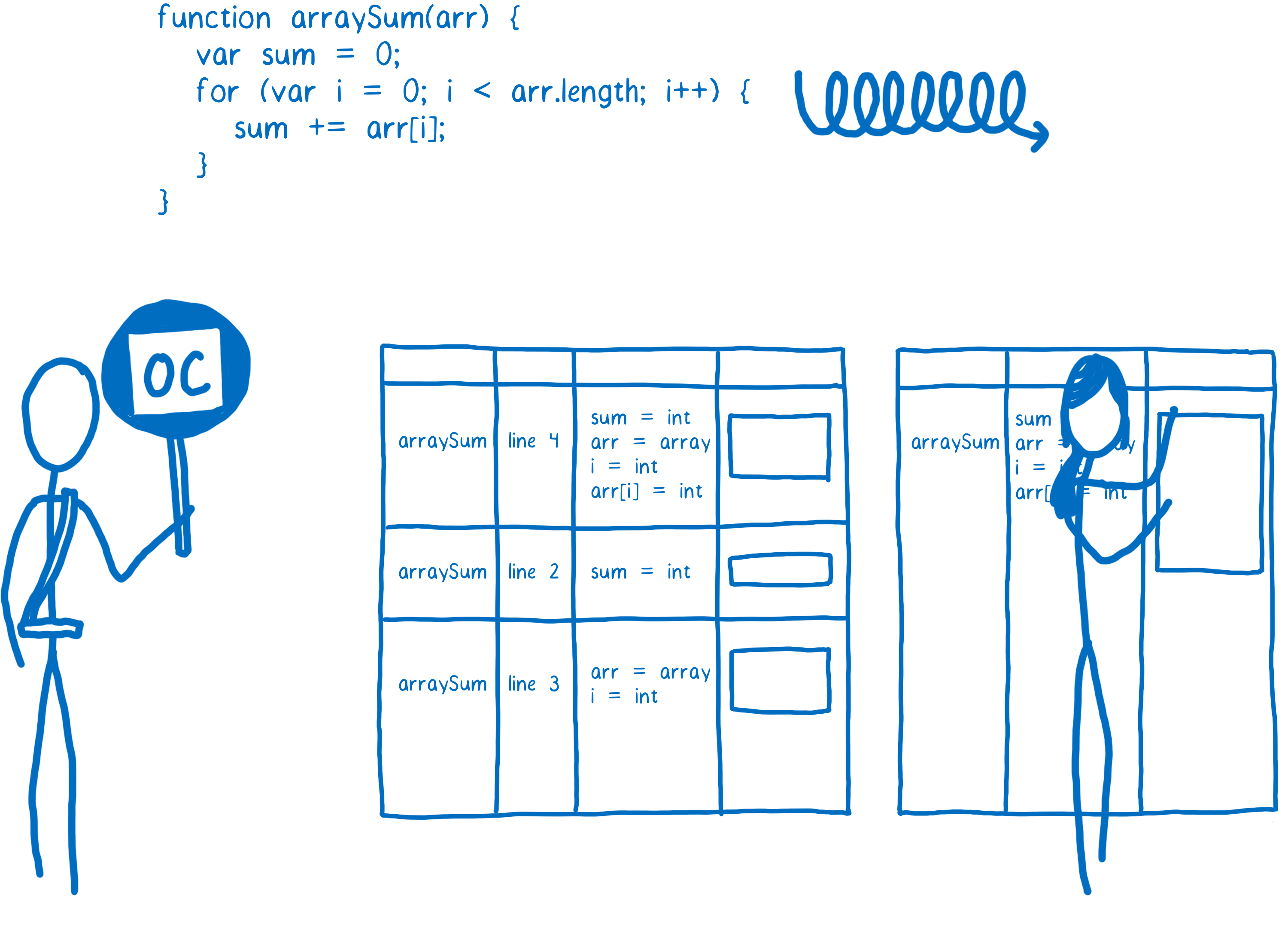
Pour pouvoir réaliser une version plus rapide du code, le compilateur va devoir émettre quelques hypothèses. Par exemple, s’il peut supposer que tous les objets créés par un constructeur donné auront toujours la même structure — en clair, s’ils ont toujours les même propriétés et que ces propriétés sont toujours instanciées dans le même ordre — alors il va prendre des raccourcis pour ce cas spécifique.
Le compilateur utilise les informations que le profileur a glanées à force d’observations pour formuler de telles hypothèses. Si quelque chose s’est révélé vrai pour toutes les boucles précédentes, alors il partira du principe que ça continuera à être vrai.
Bien évidemment, avec JavaScript il n’y a jamais de telles garanties. Vous pouvez avoir 99 objets qui ont tous la même structure mais le centième peut avoir une propriété manquante.
Ainsi, le compilateur a besoin de vérifier la validité des hypothèses avant de pouvoir exécuter le code. Si elles sont valides, alors on exécute le code compilé. Mais dans le cas contraire, le JIT va partir du principe que les hypothèses sont fausses et va mettre le code optimisé à la poubelle.
À ce moment-là, l’exécution du code va à nouveau se faire soit au niveau de l’interpréteur soit via le code de base compilé précédemment. On appelle ce processus la dé-optimisation (ou encore le rappel).
Habituellement, la compilation optimisée produit du code plus rapide, cependant, dans certains cas cela peut conduire à des problèmes de performance inattendus. Si vous avez du code qui n’arrête pas d’être optimisé puis dé-optimisé, vous pouvez vous retrouver avec du code plus lent à s’exécuter que la version compilée de base.
La plupart des navigateurs ont mis en place des limites pour sortir de ces cycles optimisation/dé-optimisation lorsqu’ils se présentent. Si le JIT a réalisé, disons, dix tentatives d’optimisation pour finalement devoir s’en débarrasser à chaque fois, alors il arrêtera de vouloir faire de l’optimisation.
Un exemple d’optimisation : la spécialisation de type
Il y a tout un tas d’optimisations possibles, je vais cependant vous en montrer une pour vous donner une idée de la manière dont les choses se passent. Un des gains les plus notables lors d’une compilation optimisée vient de ce que l’on appelle la spécialisation de type.
Le système de type dynamique utilisé par JavaScript requiert un peu plus de travail qu’il n’y paraît lors de l’exécution. Par exemple, prenons le code suivant:
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
L’étape += dans la boucle semble assez simple au premier abord. On pourrait penser que cela se calcule en une étape, malheureusement, à cause de la nature dynamique des types, ça va prendre plus d’étapes qu’on ne le croirait. Partons du principe que arr est un tableau (Array) de 100 entiers. Dès que le code va se réchauffer, le compilateur de base va créer un bout de code compilé pour chacune des opérations de la fonction. On va donc obtenir un bout de code pour sum += arr[i] qui va s’occuper de gérer l’opération += comme une addition d’entiers.
Cependant, il n’y a aucune garantie que sum et arr[i] soient des entiers. Puisque les types sont dynamiques en JavaScript, il est toujours possible que, lors d’une des itérations de la boucle, arr[i] soit une chaîne de caractères. Additionner des entiers et concaténer des chaînes sont deux opérations très différentes qui donneront lieu à des codes compilés très différents.
Le JIT résout ce problème en compilant un grand nombre de bouts de code différents. Si du code est monomorphique (c’est-à-dire qu’il est appelé toujours avec les mêmes types) on aura un extrait de code compilé spécifique. Si du code est polymorphique (c’est-à-dire qu’il est appelé avec différents types d’une exécution à l’autre), alors on aura un bout de code compilé pour chaque combinaison de type utilisée dans cette opération.
Ça signifie que le JIT va devoir poser pas mal de questions afin de pouvoir choisir le bon bout de code compilé à exécuter.
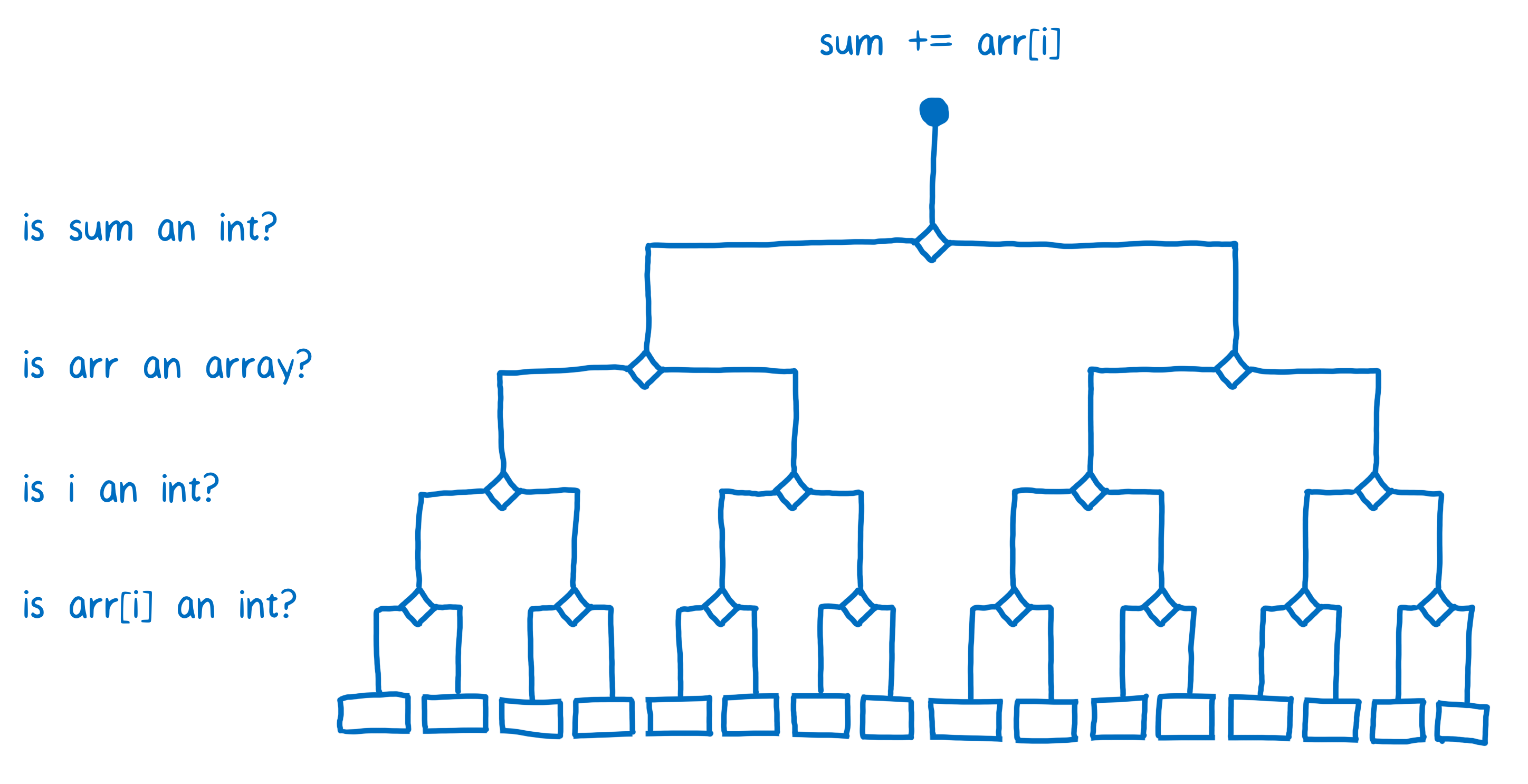
Puisque chaque ligne de code a son propre ensemble de bouts de code compilé, le JIT va devoir vérifier les types en jeu à chaque fois que la ligne de code est exécutée. Ainsi pour chaque itération de boucle, il devra sans cesse reposer les même questions.
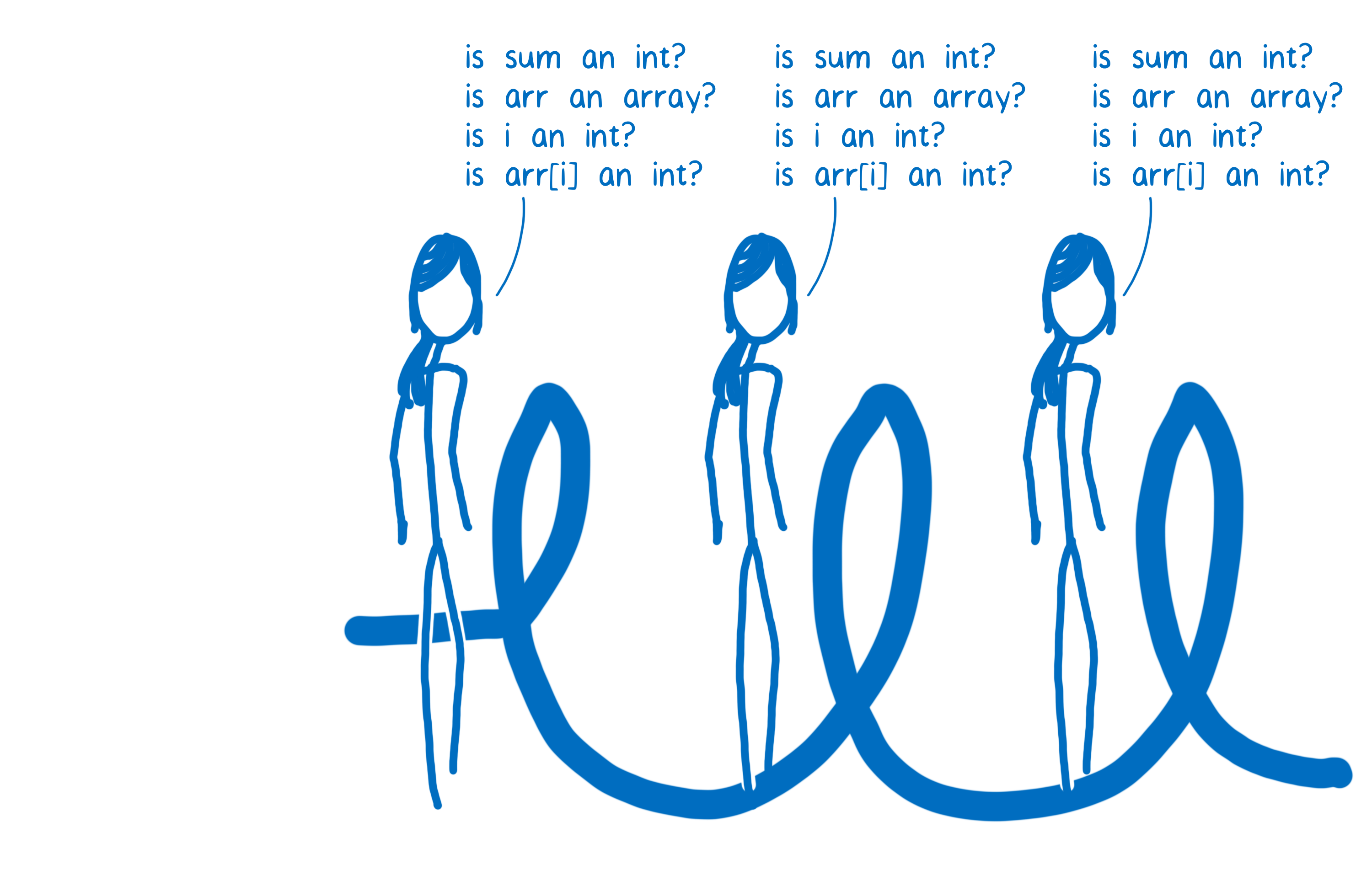
Le code s’exécuterait beaucoup plus vite si le JIT n’avait pas à répéter ces vérifications tout le temps. C’est une des choses que les compilations optimisées améliorent. Lors d’une compilation optimisée, la fonction est compilée comme un tout et la plupart des vérifications de type sont faites avant de lancer la boucle.
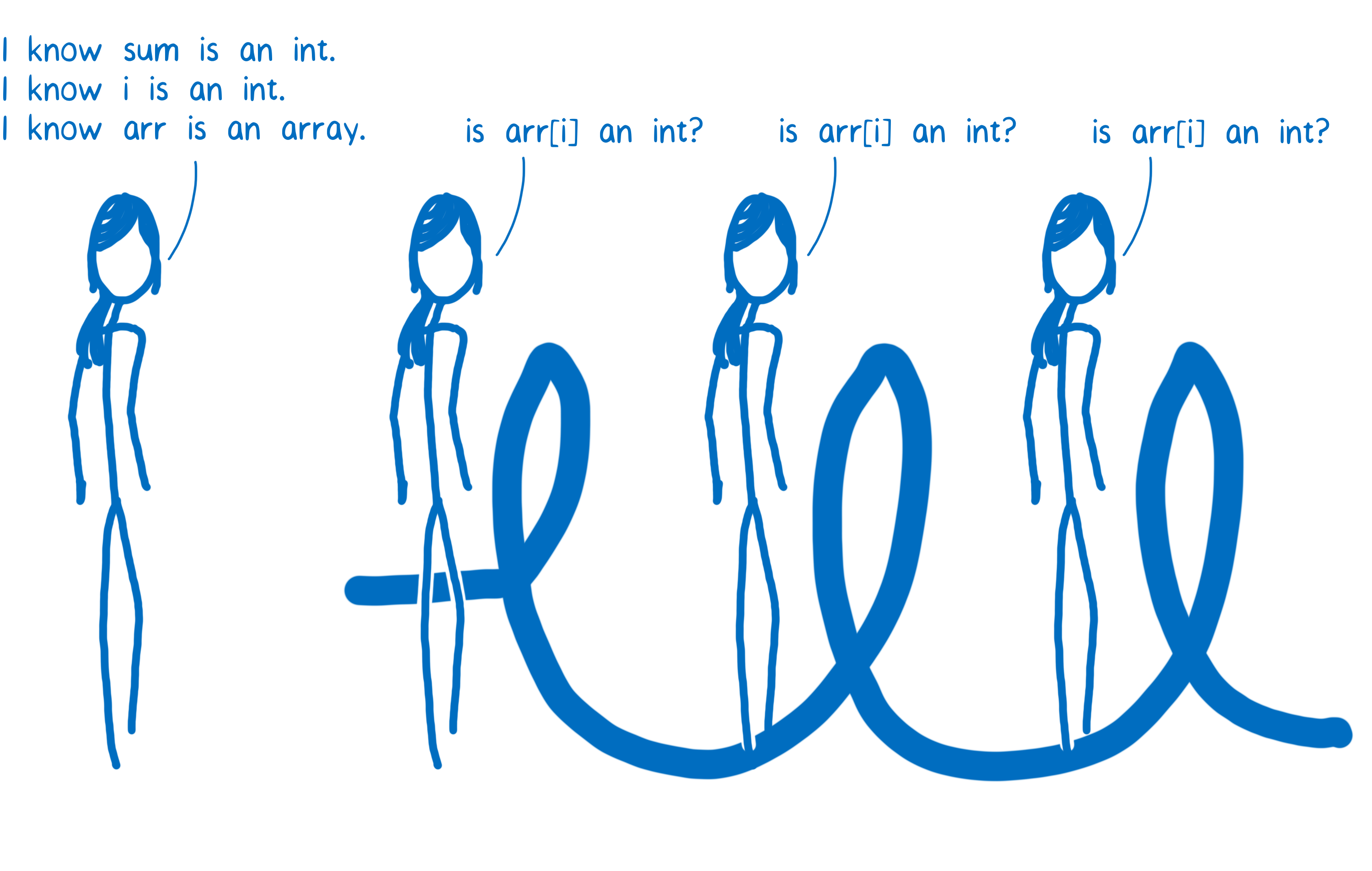
Certains JIT vont même encore plus loin. Par exemple, dans Firefox, il existe un traitement spécial réservé aux tableaux d’entiers. Si arr est un tableau de ce genre, alors le JIT n’a plus besoin de vérifier si arr[i] est un entier. L’avantage c’est que le JIT peut alors se permettre de faire toutes les vérifications de type avant le démarrage de la boucle.
Conclusion
Voilà pour une présentation rapide du fonctionnement d’un JIT. Il permet d’exécuter JavaScript plus vite en observant le code pendant son exécution et en optimisant les parties de code les plus chaudes. À bien des égards cela a conduit à une amélioration significative des performances de JavaScript pour la plupart des applications.
Et pourtant, malgré ces améliorations les performances de JavaScript restent difficiles à prédire. En plus de ça, pour rendre les chose plus rapides, le JIT ajoute de la complexité notable lors de l’exécution. En particulier :
- L’optimisation et la dé-optimisation
- L’augmentation de l’usage mémoire pour garder les informations du profileur et les informations nécessaires à le dé-optimisation
- L’augmentation de l’usage mémoire nécessaire pour stocker les différentes versions compilées d’un même code.
Il y a donc une marge de progression pour améliorer les choses : on pourrait supprimer cette complexité pour rendre les performances plus prédictibles. Et c’est justement une des choses que fait WebAssembly. Dans le prochain article, je rentrerai dans le détail de ce qu’est l’assembleur et ce qu’en font les compilateurs.
À propos de Lin Clark
Lin est ingénieure au sein de l’équipe Mozilla Developer Relations. Elle bidouille avec JavaScript, WebAssembly, Rust et Servo et crée des bandes dessinées sur le code.
