Dans l’article précédent, nous avons vu que la programmation avec WebAssembly et la programmation en JavaScript ne s’excluaient pas mutuellement. Nous ne pensons pas qu’il y aura beaucoup de développeurs qui écriront des bases de code complètes en WebAssembly.
Les développeurs n’ont donc pas à choisir entre WebAssembly et JavaScript pour développer leurs applications. Toutefois, nous pensons que les développeurs échangeront certaines parties du code JavaScript pour des modules WebAssembly.
Ainsi, l’équipe qui travaille sur React pourrait remplacer le code du DOM virtuel avec une version WebAssembly. Cela n’aurait aucun impact pour les personnes qui utilisent React. Leurs applications continueraient de fonctionner comme avant, tout en bénéficiant des avantages de WebAssembly.
Pourquoi les développeurs de React passeraient-ils cette partie du code sur un composant WebAssembly ? Parce que WebAssembly est plus rapide. Certes… mais pourquoi est-il plus rapide ?
Quel est l’état actuel des performances de JavaScript ?
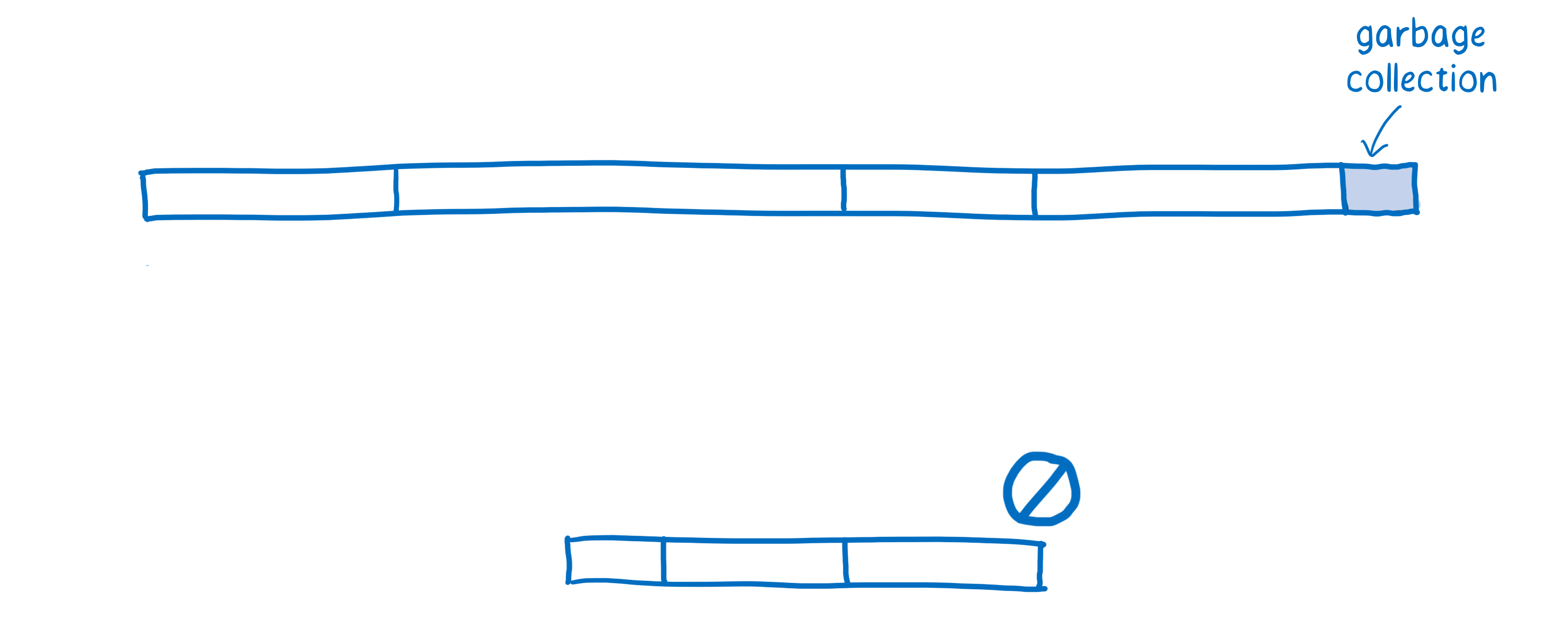
Avant de pouvoir comprendre les différences de performance entre JavaScript et WebAssembly, il faut comprendre comment fonctionne un moteur JavaScript. Ce diagramme dresse un rapide tableau des performances actuellement observées au démarrage d’une application.
Le temps consommé par le moteur JavaScript pour chacune de ces pages dépend du code JavaScript de la page. Ce diagramme n’a pas pour but d’indiquer des mesures de performance précises et chiffrées, mais de fournir un modèle général pour comparer les performances de JavaScript et celles de WebAssembly sur une phase analogue.

Chaque barre indique le temps consommé pour une tâche donnée.
- Analyse (parsing) : le temps nécessaire pour analyser le code et le transformer en quelque chose qui puisse être exécuté par l’interpréteur.
- Compilation et optimisation : le temps consommé par le compilateur et l’optimiseur. Certaines des tâches d’optimisation ne sont pas exécutées sur le thread principal, le temps correspondant n’est pas inclus ici.
- Ré-optimisation : le temps que passe le compilateur à la volée (JIT) à réajuster les hypothèses incorrectes, optimiser le code à nouveau et rediriger l’exécution vers un code moins optimisé.
- Exécution : le temps nécessaire à l’exécution du code.
- Ramasse-miettes : le temps passé à nettoyer la mémoire.
Une chose importante à noter : ces tâches ne forment pas chacune un bloc distinct et elles ne s’exécutent pas non plus dans un ordre bien défini. On a plutôt des tâches qui se recoupent, un peu d’analyse puis de l’exécution, puis de la compilation et encore de l’analyse et ensuite de l’exécution, etc.
Cette décomposition représente une avancée fondamentale par rapport aux débuts de JavaScript où on avait plutôt quelque chose comme :

Au début, lorsqu’il y avait uniquement un interpréteur qui exécutait le code JavaScript, la phase d’exécution était plutôt lente. Lorsque les compilateurs à la volée sont apparus, cela a fortement réduit le temps d’exécution.
Le prix à payer est qu’il faut désormais surveiller et compiler le code. Si les développeurs avaient continué à développer du JavaScript sur des projets de tailles analogues, les temps d’analyse et de compilation seraient très courts, mais ces améliorations de performance ont conduit les développeurs à créer des applications plus vastes. Il y a donc encore de la marge pour des améliorations.
Et WebAssembly alors ?
Voici une approximation qui illustre comment WebAssembly se comporterait pour une application web typique.
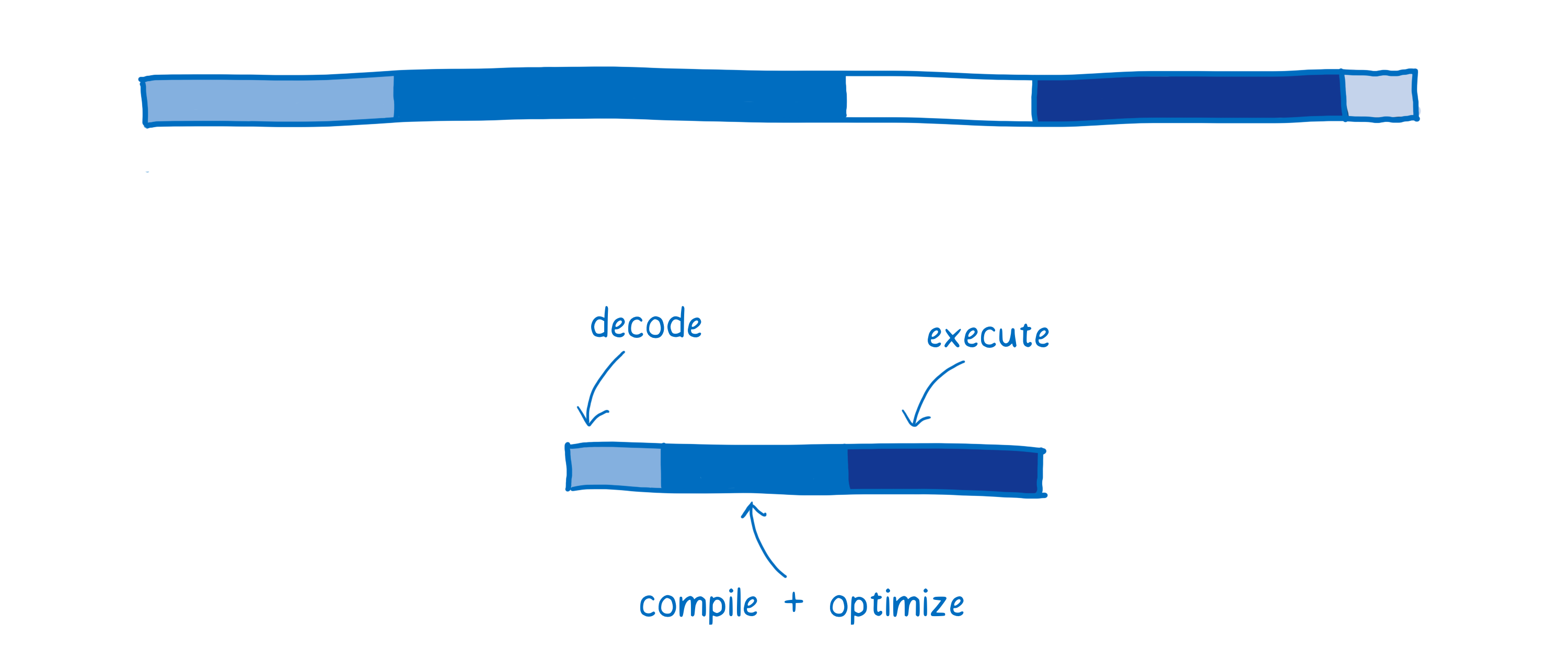
Il existe quelques variations entre les navigateurs pour ces différentes phases. Ici, j’utilise SpiderMonkey (NDT le moteur JavaScript de Firefox) comme modèle.
Le téléchargement (fetching)
Cela n’est pas montré dans le diagramme mais lorsqu’on télécharge le fichier depuis le serveur, cela prend également du temps.
WebAssembly étant plus compact que JavaScript, la récupération des fichiers est plus rapide. Bien que les algorithmes de compression puissent drastiquement réduire la taille d’un paquet de ressources JavaScript, la représentation binaire compressée d’un code WebAssembly sera tout de même plus légère.
Cela signifie qu’il faut moins de temps pour transférer les ressources depuis le serveur vers le client, notamment pour les connexions avec un débit moins élevé.
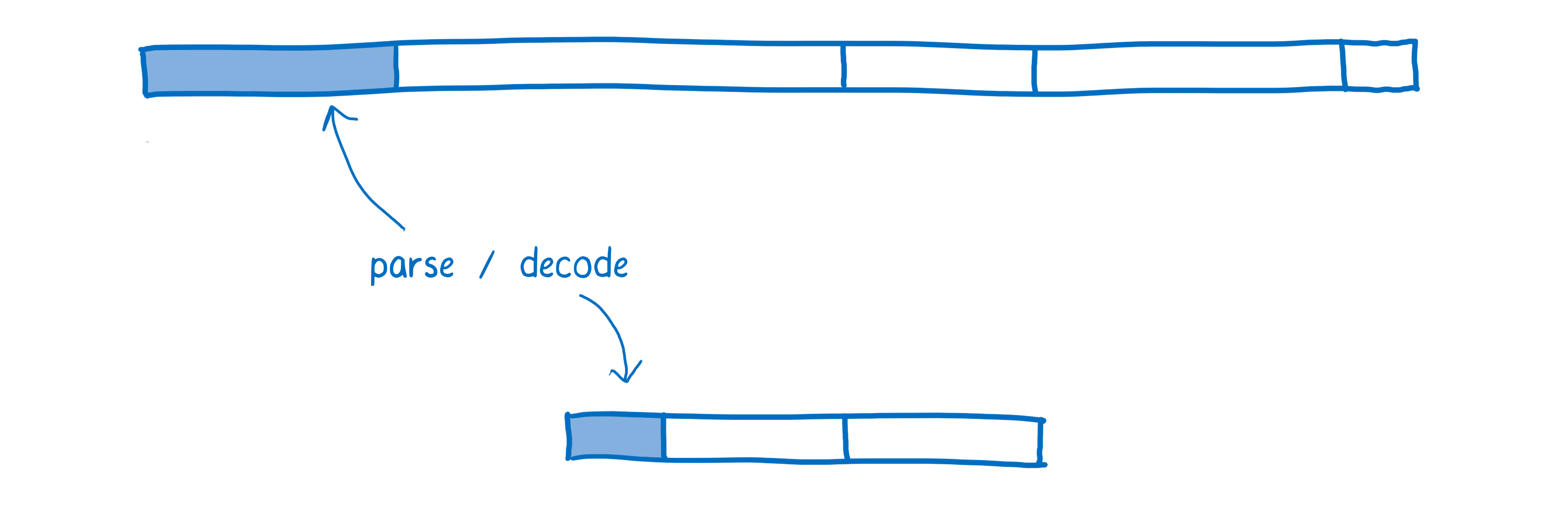
L’analyse (parsing)
Une fois que le navigateur a récupéré le fichier, le code source JavaScript est analysé afin de créer un arbre syntaxique abstrait (NDT Abstract Syntax Tree ou AST en anglais).
Les navigateurs effectuent cette analyse uniquement lorsqu’ils en ont besoin et se contentent de créer des points de références (ou stubs) pour les fonctions qui n’ont pas encore été appelées. À partir de cette étape, l’arbre syntaxique abstrait est converti en une représentation intermédiaire (aussi appelée bytecode) qui est spécifique au moteur JavaScript.
En comparaison, WebAssembly n’a pas besoin de cette phase de transformation, car il s’agit déjà d’une représentation intermédiaire. Il suffit qu’il soit décodé et validé pour vérifier qu’il ne contient pas d’erreur.
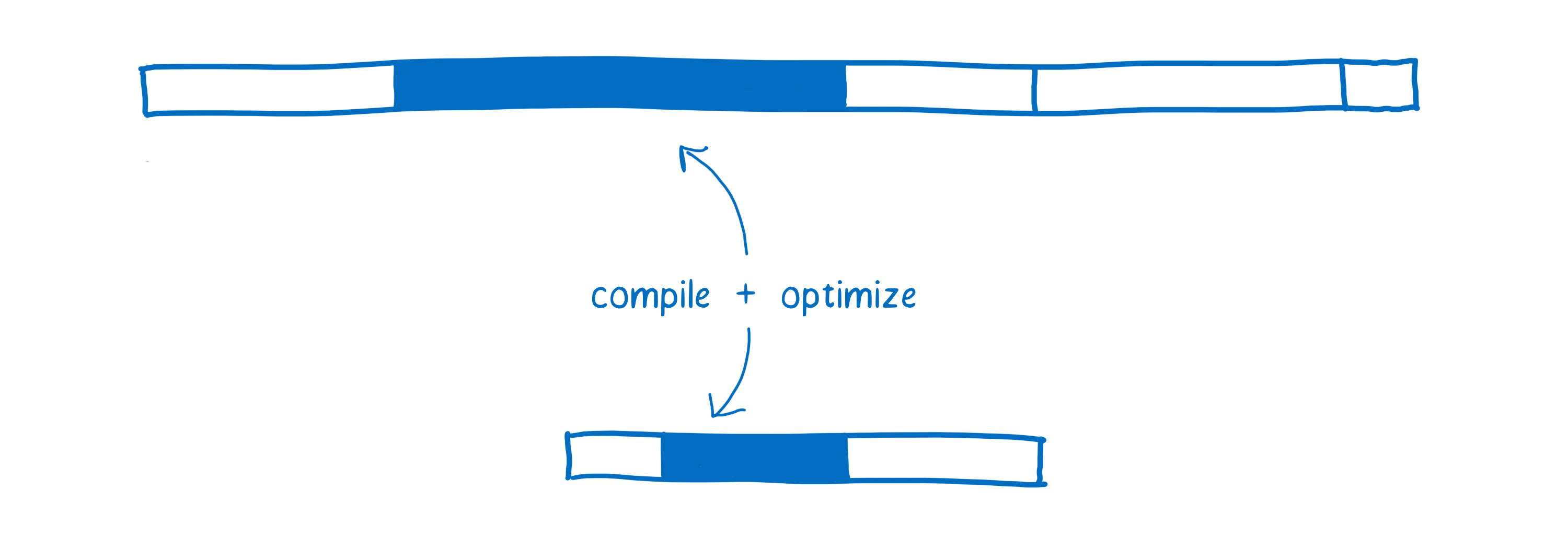
La compilation et l’optimisation
Comme nous l’avons vu dans l’article sur les compilateurs à la volée (JIT), JavaScript est compilé pendant l’exécution du code. Selon les types utilisés pendant l’exécution, on peut avoir plusieurs versions du même code qui ont besoin d’être compilées.
Les différents navigateurs ont chacun leur approche pour compiler du code WebAssembly. Certains navigateurs lancent une compilation minimale du code WebAssembly avant de l’exécuter, d’autres utilisent une compilation à la volée.
Dans tous les cas, à l’état initial, WebAssembly est déjà beaucoup plus proche du code machine. Les types de données font par exemple partie du programme. Cette phase est plus rapide pour plusieurs raisons :
- Le compilateur n’a pas besoin de passer du temps à exécuter le code pour surveiller les types à utiliser avant de commencer à compiler un code optimisé.
- Le compilateur n’a pas besoin de compiler différentes versions du même code selon les différents types observés.
- Des optimisations ont déjà été appliquées en amont par LLVM. Il faut donc moins de travail pour la compilation et l’optimisation.
La deuxième passe d’optimisation
Il arrive parfois que le compilateur à la volée doive rejeter une version du code pour l’observer de nouveau.
Cela se produit lorsque les hypothèses utilisées par le compilateur à la volée selon le code exécuté s’avèrent incorrectes. C’est par exemple le cas lorsque des variables utilisées dans une boucle sont différentes par rapport aux itérations précédentes ou lorsqu’une nouvelle fonction est insérée dans la chaîne de prototypes.
Cela consomme du temps pour deux raisons. Premièrement, il faut repasser du code optimisé au code de base, ce qui prend du temps. Deuxièmement, si une fonction continue d’être appelée fréquemment, le compilateur à la volée peut choisir de la passer à nouveau à l’optimiseur : on a alors le coût en temps d’une deuxième compilation.
En WebAssembly, les paramètres tels que les types sont explicites. Le compilateur à la volée n’a donc pas besoin d’émettre des hypothèses sur les types à partir des données récupérées pendant l’exécution. Cela signifie qu’il n’est pas nécessaire de passer par ces cycles de ré-optimisation.

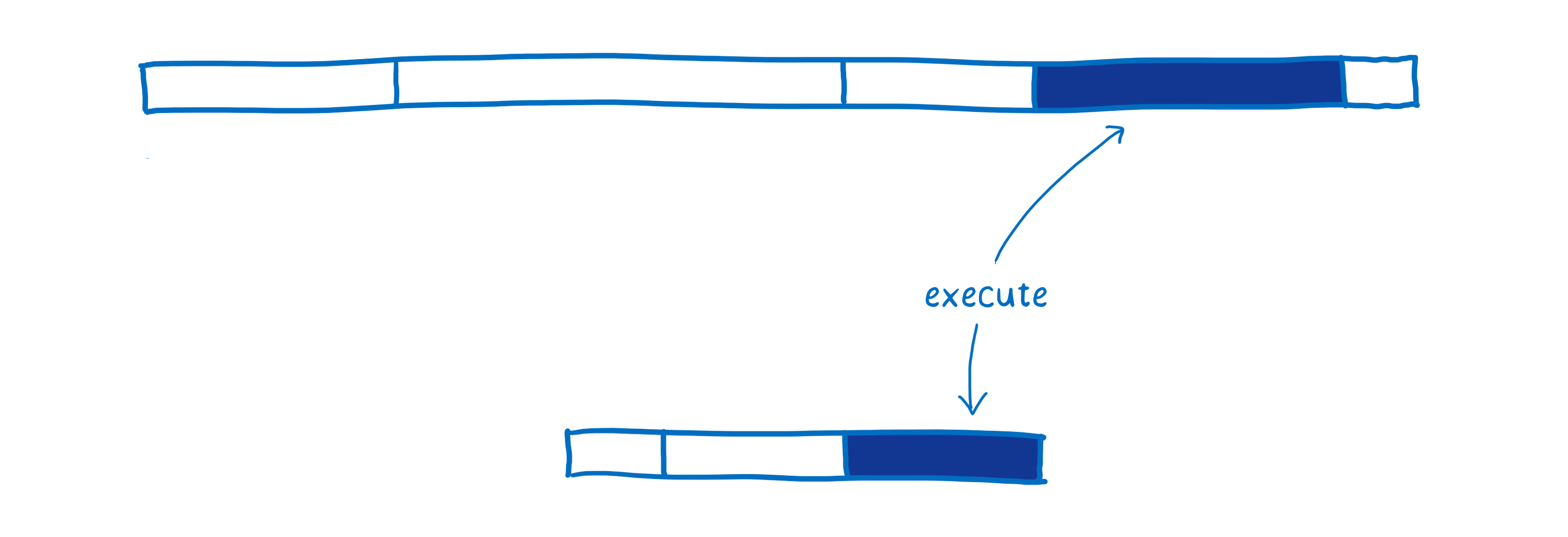
L’exécution
Il est tout à fait possible d’écrire du JavaScript qui est exécuté de façon performante. Pour cela, il est nécessaire de connaître les optimisations qui sont réalisées par le compilateur à la volée. Il faut par exemple savoir comment écrire du code afin que le compilateur puisse opérer une spécialisation de type (cf. l’article sur la compilation JIT).
Cependant, la plupart des développeurs ne connaissent pas ces détails de compilation. Et même pour les développeurs qui connaissent ces notions, obtenir le bon équilibre est parfois difficile. Certaines méthodes utilisées pour rendre le code plus lisible (comme créer des tâches abstraites génériques qui fonctionnent quel que soit le type utilisé) vont à l’encontre du compilateur lorsqu’il s’agit d’optimiser le code.
De plus, les optimisations utilisées par un compilateur JIT varient d’un navigateur à l’autre et développer « pour » un navigateur donné peut ne pas avoir l’effet escompté voire l’effet inverse…
Étant donné ces différentes raisons, l’exécution de code WebAssembly est généralement plus rapide. La plupart des optimisations réalisées par le compilateur à la volée pour JavaScript (comme la spécialisation de type) ne sont pas nécessaires pour WebAssembly.
En outre, WebAssembly a été conçu comme une cible de compilation. Cela signifie qu’il a été conçu pour être généré par des compilateurs et pas pour être écrit par des humains.
Les développeurs n’ayant pas besoin de programmer directement en WebAssembly, celui-ci peut utiliser un ensemble d’instructions plus adaptées aux machines. Selon la tâche réalisée par votre code, ces instructions peuvent s’exécuter 10 % à 800 % plus rapidement.
La gestion du ramasse-miettes
En JavaScript, le développeur n’a pas à se soucier de la mémoire utilisée par des variables devenues inutiles. C’est le moteur JavaScript qui s’occupe automatiquement de cette tâche grâce à ce qu’on appelle un ramasse-miettes.
Cela peut toutefois poser problème si on souhaite avoir des performances prédictibles. On ne maîtrise pas le moment où le ramasse-miettes sera actif et ça peut très bien être au mauvais moment. La plupart des navigateurs sont désormais assez affutés pour déclencher le ramasse-miettes quand il faut mais cela représente toujours une dépense de ressources et de temps qui peut ralentir l’exécution du code.
À l’heure actuelle, WebAssembly fonctionne sans aucun ramasse-miettes. La mémoire doit être gérée manuellement (comme c’est le cas avec des langages comme C ou C++). Bien que cela rende le développement plus complexe, cela permet également d’obtenir des performances plus stables.
Conclusion
À de nombreux égards, WebAssembly est plus rapide que JavaScript :
- La récupération des ressources WebAssembly prend moins de temps, car le code WebAssembly est plus compact que le code JavaScript même lorsque ce dernier est compressé.
- Le décodage du code WebAssembly prend moins de temps que l’analyse syntaxique du code JavaScript.
- La compilation et l’optimisation du code WebAssembly prend moins de temps car celui-ci est plus proche du code machine et a déjà subi certaines optimisations du générateur de code wasm (par ex. LLVM) en amont.
- Les passes d’optimisation successives ne sont pas nécessaires en WebAssembly, car les types et les autres informations font partie du code. Le moteur JavaScript n’a donc pas besoin d’émettre des hypothèses comme il le fait pour du code JavaScript classique.
- L’exécution est généralement plus rapide, car il y a moins d’astuces/pièges à connaître pour écrire du code qui soit cohérent et performant. De plus l’ensemble des instructions WebAssembly est plus adapté aux machines.
- Le ramasse-miettes n’est pas utilisé avec WebAssembly, car la mémoire est gérée manuellement.
C’est pour ces différentes raisons que dans de nombreux cas, WebAssembly sera plus performant que JavaScript pour réaliser une même tâche.
Il existe certains cas où WebAssembly n’est pas aussi performant qu’il devrait l’être. Certains changements sont également en cours pour rendre WebAssembly plus rapide. C’est ce que nous verrons dans le prochain article.
À propos de Lin Clark
Lin est ingénieure au sein de l’équipe Mozilla Developer Relations. Elle bidouille avec JavaScript, WebAssembly, Rust et Servo et crée des bandes dessinées sur le code.
