Ce billet est une traduction de l’excellent billet de Mary Rose Cook, Git from the inside out. On y apprend vraiment plein de choses sur le fonctionnement de Git.
Il se peut qu’il reste quelques coquilles, n’hésitez pas à me les signaler.
Je tiens à remercier Pierre Ozoux, goofy, Agnès H, Stéphane Hulard, Jums, Julien aka Sphinx et xi de m’avoir aidé à traduire ce très très long billet.
Cet article explique comment fonctionne Git. Il part du principe que vous comprenez suffisamment Git pour l’utiliser en tant que système de gestion de versions pour vos projets.
Cet article se concentre sur la structure de graphe sur laquelle s’appuie Git et sur la manière dont les propriétés de ce graphe dictent le comportement de Git. Revenir aux bases vous permet de visualiser les choses telles qu’elles sont réellement, et vous évite d’échafauder des hypothèses à partir du fonctionnement de l’API. Ce modèle, plus fidèle à la réalité, vous permettra de mieux comprendre ce que Git a fait, ce qu’il fait et ce qu’il fera.
Cet article est structuré comme une série de commandes Git exécutées sur un projet. Par moments, il y a des remarques à propos de la structure de données en graphe sur laquelle Git est construit. Ces remarques illustrent une propriété du graphe et le comportement provoquée par celle-ci.
Après votre lecture, si vous voulez aller plus loin avec Git, vous pouvez regarder sur le code source annoté de mon implémentation de Git en JavaScript.
Créer le projet
~ $ mkdir alpha
~ $ cd alpha
L’utilisateur crée alpha, un répertoire pour son projet.
~/alpha $ mkdir data
~/alpha $ printf 'a' > data/letter.txt
Il se rend dans le répertoire alpha et crée un répertoire data. À l’intérieur, il crée un fichier appelé letter.txt qui contient le caractère a. Le répertoire alpha ressemble donc à ceci :
alpha
└── data
└── letter.txt
Initialisation du dépôt
~/alpha $ git init
Dépôt Git vide initialisé
git init transforme le répertoire courant en dépôt Git. Pour faire cela, il crée un répertoire .git et écrit quelques fichiers dedans. Ces fichiers définissent tout ce qui concerne la configuration Git et l’historique du projet. Ce sont des fichiers classiques. Rien d’extraordinaire. L’utilisateur peut les lire et les éditer avec un éditeur de texte ou avec son terminal. Ce qui revient à dire : l’utilisateur peut lire et modifier l’historique de son projet aussi facilement que les fichiers du projet.
Le répertoire alpha ressemble maintenant à ça :
alpha
├── data
| └── letter.txt
└── .git
├── objects
etc.
Le répertoire .git et son contenu appartiennent à Git. Tous les autres fichiers sont considérés comme la copie de travail. Ils appartiennent à l’utilisateur.
Ajouter quelques fichiers
~/alpha $ git add data/letter.txt
L’utilisateur exécute git add sur le fichier data/letter.txt. Cela a deux effets.
Tout d’abord, cela crée un nouveau fichier binaire dans le répertoire .git/objects/.
Ce fichier binaire contient le contenu compressé de data/letter.txt. Son nom est basé sur le contenu haché du fichier. Hacher du texte veut dire qu’un programme le convertit en un texte plus petit 1 qui identifie de manière unique 2 le texte original. Par exemple, Git hache le caractère a en 2e65efe2a145dda7ee51d1741299f848e5bf752e. Les deux premiers caractères sont utilisés comme nom de répertoire dans la base de données des objets : .git/objects/2e/. Le reste du hachage est utilisé comme nom pour le fichier binaire qui contient le contenu du fichier ajouté : .git/objects/2e/65efe2a145dda7ee51d1741299f848e5bf752e.
Notez que le simple fait d’ajouter un fichier à Git sauvegarde son contenu dans le répertoire objects. Son contenu restera intact dans Git si l’utilisateur supprime le fichier data/letter.txt de sa copie de travail.
Ensuite, git add ajoute le fichier à l’index. L’index est une liste qui contient chaque fichier dont Git doit conserver une trace. Il est stocké comme fichier ici : .git/index. Chaque ligne du fichier associe un fichier suivi au hachage de son contenu au moment où il a été ajouté. Voici l’index après l’exécution de la commande git add :
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e
L’utilisateur crée un fichier appelé data/number.txt qui contient 1234.
~/alpha $ printf '1234' > data/number.txt
Le répertoire de travail correspond donc à ça :
alpha
└── data
└── letter.txt
└── number.txt
L’utilisateur ajoute le fichier à Git.
~/alpha $ git add data
La commande git add crée un fichier binaire qui contient le contenu de data/number.txt. Elle ajoute une entrée dans l’index pour le fichier data/number.txt qui pointe vers le fichier binaire. Voici l’index après l’exécution, pour la deuxième fois, de la commande git add :
data/letter.txt 2e65efe2a145dda7ee51d1741299f848e5bf752e
data/number.txt 274c0052dd5408f8ae2bc8440029ff67d79bc5c3
Notez que seuls les fichiers dans le répertoire data sont listés dans l’index malgré le fait que l’utilisateur ait exécuté la commande git add data. Le répertoire data n’est pas listé séparément.
~/alpha $ printf '1' > data/number.txt
~/alpha $ git add data
Quand l’utilisateur a créé data/number.txt, il voulait taper 1 et non 1234. Il effectue la correction et ajoute de nouveau le fichier à l’index. La commande crée un nouveau fichier binaire avec le nouveau contenu. Et elle met à jour l’entrée dans l’index pour data/number.txt pour pointer vers ce nouveau fichier binaire.
Faire un commit
~/alpha $ git commit -m 'a1'
[master (commit-racine) 774b54a] a1
L’utilisateur crée le « commit » a1. Git affiche quelques infos à propos du commit. La signification de ces informations sera plus claire dans quelques paragraphes. La commande commit est faite en trois étapes. Elle crée un arbre qui représente le contenu de la version du projet à commiter. Elle crée un objet de commit. Elle pointe la branche courante sur ce nouvel objet de commit.
Créer un arbre
Git enregistre l’état courant du projet en créant un arbre depuis l’index. Cet arbre enregistre l’emplacement et le contenu de chaque fichier dans le projet.
Ce graphe est composé de deux types d’objet : des fichiers binaires et des arbres.
Les fichiers binaires sont stockés par la commande git add. Ils représentent le contenu des fichiers.
Les arbres sont stockés quand un commit est créé. Un arbre représente un répertoire dans la copie de travail.
Voici un arbre qui enregistre les contenus du répertoire data pour le nouveau commit :
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob 56a6051ca2b02b04ef92d5150c9ef600403cb1de number.txt
La première ligne enregistre tout ce qui est nécessaire pour reproduire le fichier data/letter.txt. La première partie correspond aux permissions du fichier. La seconde partie correspond au contenu de l’entrée, représentée par un fichier binaire plutôt que par un arbre. La troisième partie correspond à l’empreinte du fichier binaire. La quatrième partie correspond au nom du fichier.
La deuxième enregistre la même chose pour data/number.txt.
Voici un arbre pour le répertoire alpha, qui est le répertoire racine du projet :
040000 tree 0eed1217a2947f4930583229987d90fe5e8e0b74 data
La seule ligne dans cet arbre pointe vers l’arbre data.
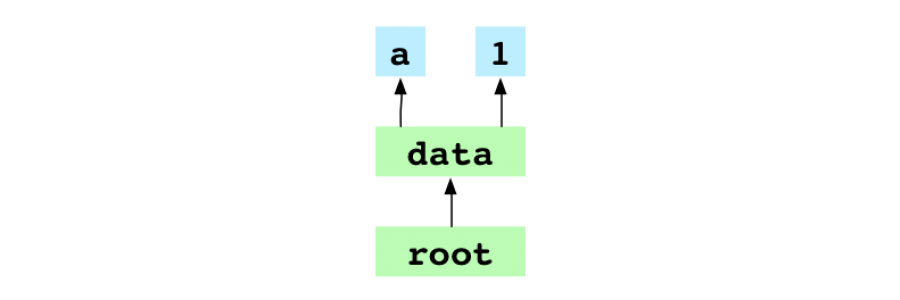
Image : L’arbre pour le commit a1
Dans le graphe ci-dessus, l’arbre root pointe vers l’arbre data. L’arbre data pointe vers les fichiers binaires pour data/letter.txt et data/number.txt.
Créer un objet de commit
git commit crée un objet de commit après la création de l’arbre. L’objet de commit est simplement un autre fichier texte dans .git/objects/.
tree ffe298c3ce8bb07326f888907996eaa48d266db4
author Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1424798436 -0500
a1
La première ligne pointe vers l’arbre. L’empreinte correspond à l’objet qui représente la racine de la copie de travail, c’est-à-dire le répertoire alpha. La dernière ligne correspond au commit.

Image : L’objet pour le commit a1 qui pointe vers son arbre
Placer la branche actuelle sur le nouveau commit
Finalement, la commande commit place la branche courante sur le nouvel objet commit. Quelle est la branche actuelle ? Git va dans le fichier HEAD se trouvant dans .git/HEAD et trouve :
ref: refs/heads/master
Cela signifie que HEAD pointe sur master. master est la branche actuelle. HEAD et master sont toutes les deux des références. Une référence est un libellé utilisé par Git ou l’utilisateur pour identifier un commit spécifique. Ce fichier que représente la référence master n’existe pas, parce que c’est le premier commit dans le dépôt. Git crée le fichier .git/refs/heads/master et y inscrit l’empreinte de l’objet de commit :
74ac3ad9cde0b265d2b4f1c778b283a6e2ffbafd
(Si vous exécutez ces commandes Git pendant que vous lisez, l’empreinte de votre commit a1 sera différente de celle que j’ai obtenue ici. Les objets de contenu comme les fichiers binaires et les arbres sont toujours hachés avec la même valeur. En revanche, l’empreinte d’un commit peut varier car un commit inclut une date et le nom de son créateur.)
Ajoutons HEAD et master sur le graphe Git :
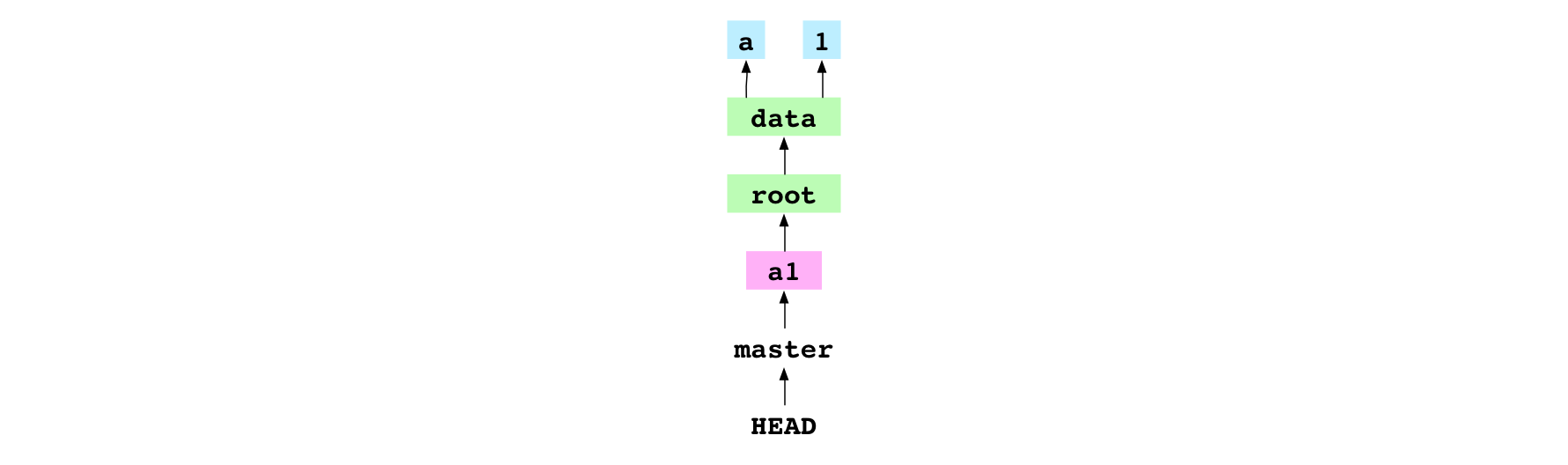
Image : HEAD pointant sur master et master pointant sur le commit a1
HEAD pointe sur master, comme elle le faisait avant le commit. Mais désormais, master existe et pointe sur le nouvel objet de commit.
Créer un commit qui n’est pas le premier commit
Ci-dessous, on voit le graphe Git après le commit a1 avec le contenu de la copie de travail et l’index.
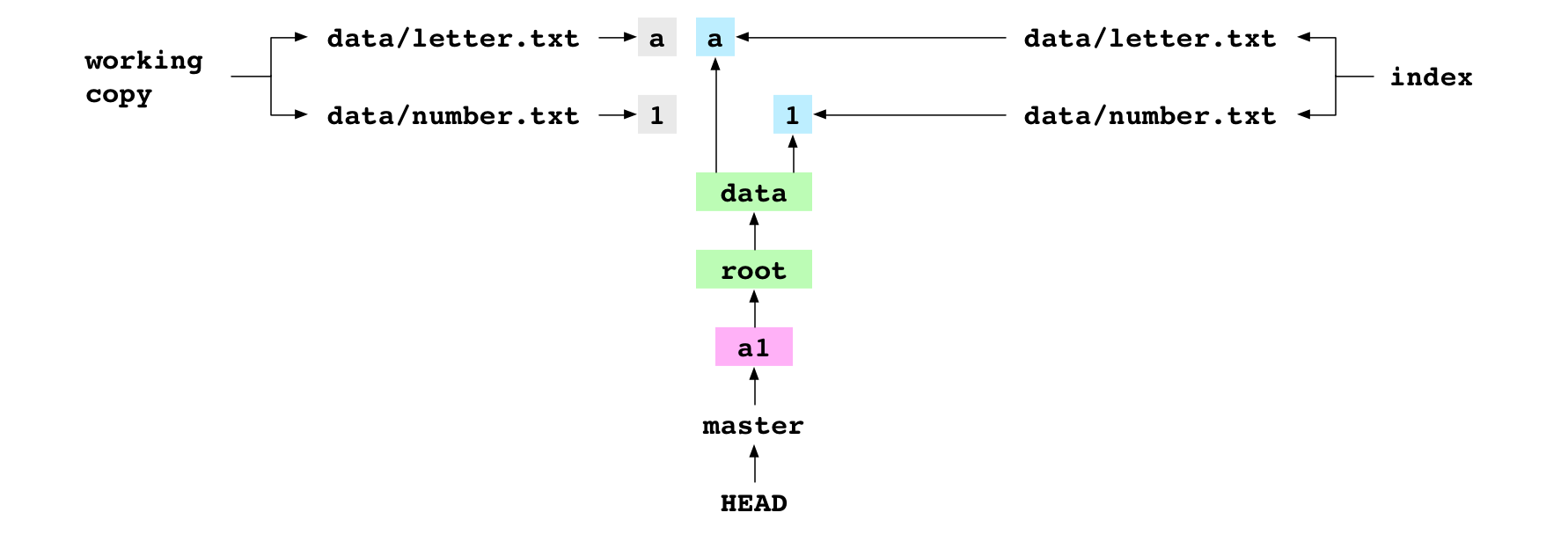
Image : Le commit a1, affiché avec la copie de travail et l’index
Notez que la copie de travail, l’index et le commit a1 ont tous le même contenu pour data/letter.txt et data/number.txt. L’index et le commit HEAD utilisent tous les deux des empreintes pour se référer aux objets binaires, mais le contenu de la copie de travail est stockée sous forme de texte dans un autre endroit.
~/alpha $ printf '2' > data/number.txt
L’utilisateur initialise le contenu de data/number.txt à 2. Cette action met à jour la copie de travail mais laisse l’index et le commit HEAD tels quels.
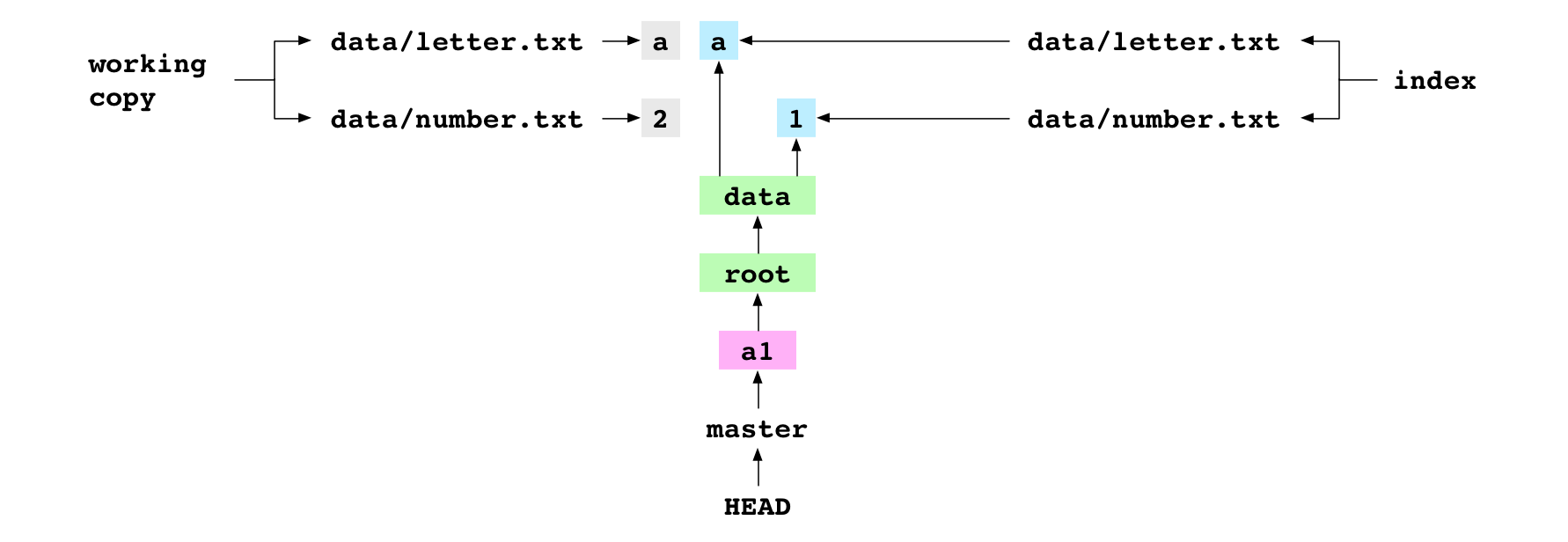
Image : data/number.txt initialisé à 2 dans la copie de travail
~/alpha $ git add data/number.txt
L’utilisateur ajoute le fichier à Git. Cela rajoute un fichier binaire qui contient 2 dans le répertoire objects. Il pointe sur l’entrée de l’index pour data/number.txt sur le nouvel objet binaire.
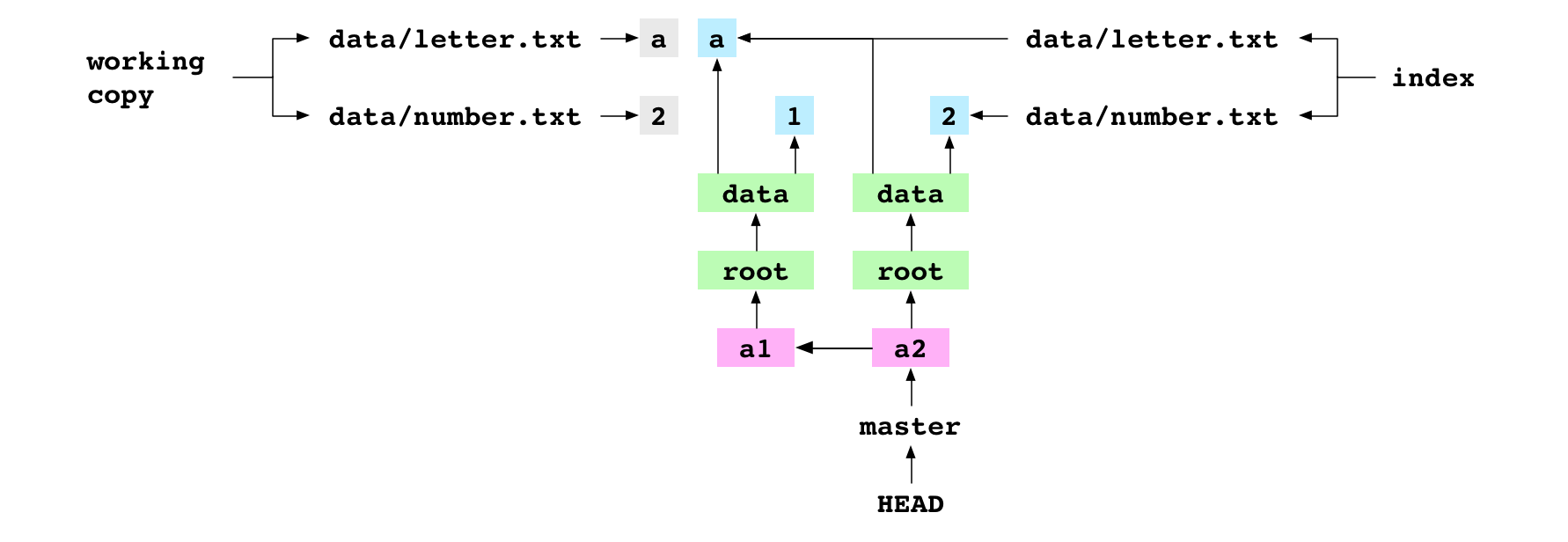
Image : data/number.txt initialisé à 2 dans la copie de travail et dans l’index
~/alpha $ git commit -m 'a2'
[master f0af7e6] a2
L’utilisateur ajoute un commit. Les étapes pour le commit sont les mêmes que précédemment.
Tout d’abord, un nouvel arbre/graphe est créé pour représenter le contenu de l’index.
Dans l’index, l’entrée pour data/number.txt a changé. L’ancien arbre data ne correspond plus à l’état indexé du repertoire data. Un nouvel arbre data doit être créé :
100664 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt
100664 blob d8263ee9860594d2806b0dfd1bfd17528b0ba2a4 number.txt
La nouvelle empreinte (hash) correspondant à l’arbre data est différente de la précédente. Un nouvel arbre root doit être créé pour enregistrer cette nouvelle empreinte :
040000 tree 40b0318811470aaacc577485777d7a6780e51f0b data
Deuxièmement, un nouvel objet de commit est créé.
tree ce72afb5ff229a39f6cce47b00d1b0ed60fe3556
parent 774b54a193d6cfdd081e581a007d2e11f784b9fe
author Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1424813101 -0500
a2
La première ligne de ce commit pointe vers le nouvel arbre root. La deuxième ligne pointe vers a1 : le commit parent. Pour trouver le commit parent, Git est allé sur la référence HEAD puis a suivi sur master et a trouvé l’empreinte du commit a1.
Troisièmement, Git inscrit l’empreinte du nouveau commit dans le fichier qui décrit la branche master.
Image : Le commit a2
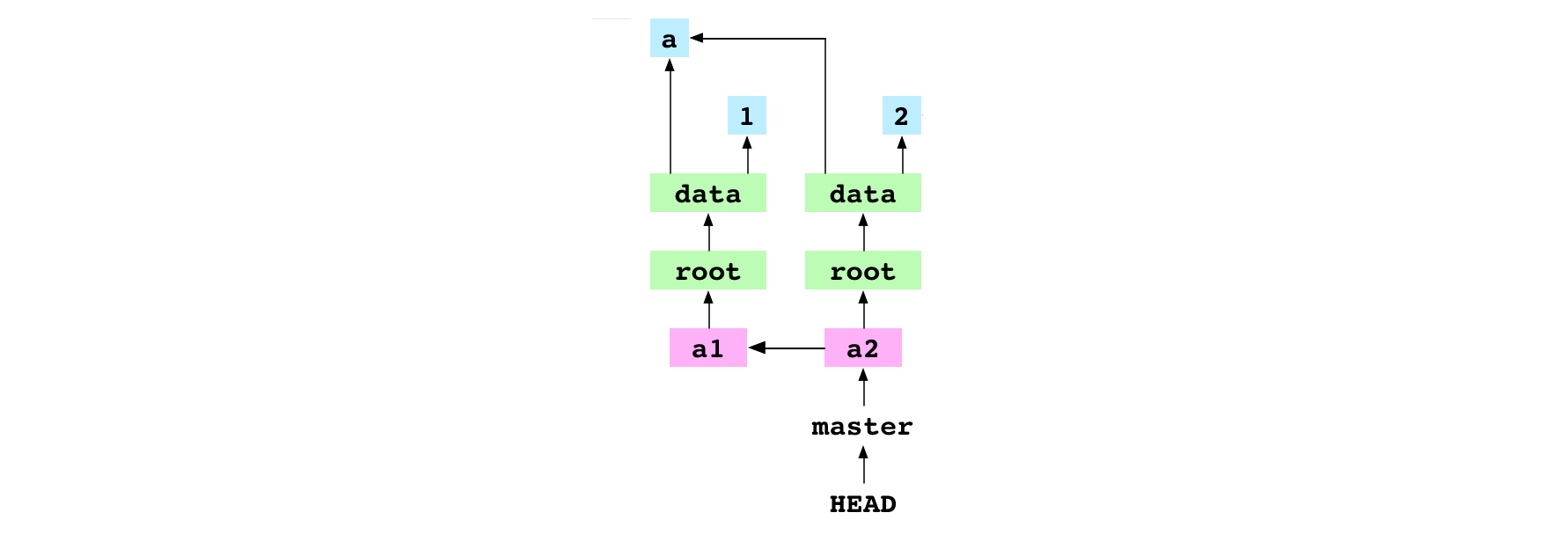
Image : Le graphe Git, sans index ni copie de travail
Propriété du graphe : le contenu est stocké en tant qu’arbre d’objets. Ce qui signifie que seules les différences entre les objets sont stockées dans la base de données des objets. Observez le graphe ci-dessus. Le commit a2 réutilise le fichier binaire qui a été créé avant le commit a1. Si le répertoire entier reste inchangé de commit en commit, alors son arbre et tous les blobs et arbres enfants pourront être réutilisés. En général, il n’y a que peu de changements d’un commit à un autre. Cela signifie que Git peut stocker un large historique de commits dans un très petit espace.
Propriété du graphe : chaque commit a un parent. Ce qui signifie qu’un répertoire peut stocker l’historique du projet.
Propriété du graphe : les références (ref) sont les points d’entrée vers une partie de l’historique de commit. Cela signifie qu’un commit peut être nommé de façon adéquate. L’utilisateur peut organiser son travail sous la forme de lignées de commits pertinentes pour un projet et les intituler avec des références concrètes, par exemple fix-for-bug-376. Git utilise des références symboliques telles que HEAD, MERGE_HEAD et FETCH_HEAD pour les commandes qui manipulent l’historique des commits.
Propriété du graphe : les nœuds du répertoire objects/ sont immuables. Ceci signifie que le contenu est édité, pas effacé. Tout ce qui a jamais été ajouté et tous les commits qui ont été réalisés se trouvent quelque part dans le répertoire objects3.
Propriété du graphe : les références (refs) sont modifiables. Par conséquent, la signification d’une référence peut changer. Le commit vers lequel pointe la branche master peut être la meilleure version existante d’un projet, mais très vite, il sera remplacé par un meilleur commit plus récent.
Propriété du graphe : la copie de travail et les commits vers lesquels pointent les références sont facilement accessibles mais les autres commits ne le sont pas. Ceci signifie que l’historique récent est plus facilement accessible, mais aussi qu’il change plus souvent. Autrement dit, Git a une mémoire vacillante qui doit souvent être rafraîchie.
La copie de travail est le point de l’historique le plus facile à accéder parce qu’elle est à la racine du répertoire. Y accéder ne nécessite même pas l’utilisation d’une commande Git. C’est aussi le point le moins fixe de l’historique. L’utilisateur peut faire une dizaine de versions d’un fichier mais Git n’en enregistrera aucune à moins qu’elles ne soient ajoutées.
On peut très facilement se souvenir du commit sur lequel pointe HEAD. Cette référence est à l’extrémité de la branche sur laquelle on travaille. Pour voir son contenu, l’utilisateur peut mettre de côté (stash)4 ses modifications et examiner la copie de travail. La référence HEAD est donc également celle qui change le plus souvent.
On peut facilement se souvenir du commit sur lequel pointe une référence concrète. Pour ce faire, l’utilisateur peut simplement basculer sur la branche correspondante. L’extrémité d’une branche évolue moins fréquemment que HEAD mais suffisamment pour que le nom de la branche traduise quelque chose qui évolue.
Il est plus difficile de se rappeler un commit pour lequel il n’existe aucune référence. Plus on s’écarte d’une référence, plus il est difficile de reconstituer le sens d’un commit. Cela dit, plus on s’éloigne d’une référence, moins il y a de chances que quelqu’un ait modifié l’historique depuis la dernière fois qu’on l’a consulté5.
Basculer sur un commit
~/alpha $ git checkout 37888c2
You are in 'detached HEAD' state...
L’utilisateur bascule sur le commit a2 en utilisant son empreinte. (Si vous lancez cette commande Git telle quelle, elle ne fonctionnera pas. Vous devez utiliser git log afin de trouver l’empreinte qui correspond au commit a2.)
Le basculement se fait en quatre étapes.
Premièrement, Git récupère le commit a2 et le graphe vers lequel il pointe.
Deuxièmement, il écrit les fichiers listés dans le graphe dans la copie de travail. Ici, cela ne produit aucune modification car la copie de travail contient déjà les mêmes fichiers que le graphe car HEAD pointait déjà, via la branche master, sur le commit a2.
Troisièmement, Git écrit la liste des fichiers du graphe dans l’index. Là encore, aucune modification n’est appliquée. L’index contient déjà le contenu du commit a2.
Enfin, lors de la quatrième étape, HEAD est mis à jour avec l’empreinte du commit a2 :
f0af7e62679e144bb28c627ee3e8f7bdb235eee9
Lorsque le contenu de HEAD est défini avec une empreinte, le dépôt est dans un état où la tête (HEAD) est détachée. On voit dans le schéma ci-après que HEAD pointe directement sur le commit a2 plutôt que de pointer vers master.
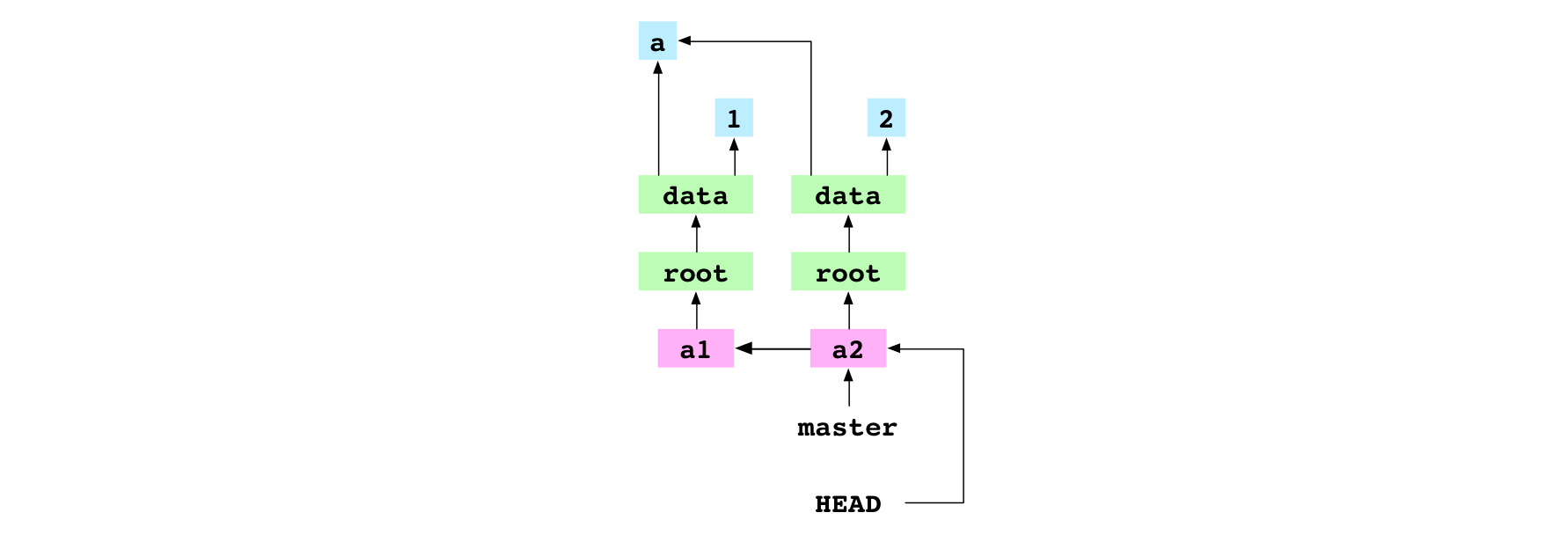
Image : La référence HEAD, détachée, sur le commit a2
~/alpha $ printf '3' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a3'
[HEAD détachée 3645a0e] a3
L’utilisateur écrit 3 dans le fichier data/number.txt puis ajoute un commit pour cette modification. Git utilise la référence HEAD pour obtenir le parent du commit a3. Plutôt que de trouver une référence de branche, Git trouve et renvoie l’empreinte du commit a2.
Git met à jour la référence HEAD pour qu’elle pointe directement sur l’empreinte du commit a3. Le depôt est alors toujours dans un état où HEAD est détachée. Elle n’est pas sur une branche car aucune référence de branche ne pointe sur le commit a3 ou l’un de ses descendants. Cela signifie qu’on peut facilement perdre le travail en cours.
À partir de maintenant, la plupart des schémas n’incluront plus les arbres et les blobs.
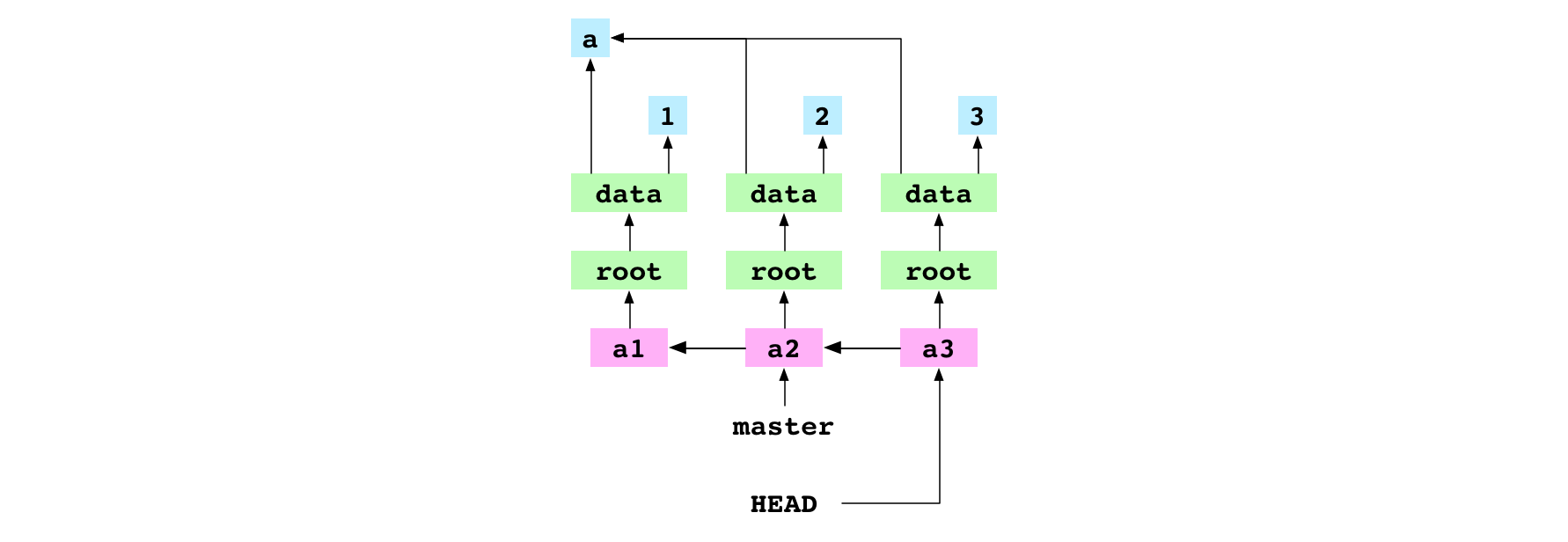
Image : Le commit a3 qui n’est pas sur une branche
Créer une branche
~/alpha $ git branch deputy
Avec cette commande, l’utilisateur crée une nouvelle branche intitulée deputy. Cette opération crée simplement un nouveau fichier situé sous .git/refs/heads/deputy et qui contient l’empreinte vers laquelle HEAD pointe, c’est-à-dire l’empreinte du commit a3.
Propriété du graphe : les branches sont simplement des références (refs) et les références sont simplement des fichiers. Cela signifie que les branches Git sont légères.
La création de la branche deputy permet d’enregistrer le commit a3 de façon sûre, sur une branche. HEAD est toujours détachée car elle pointe toujours directement vers un commit.
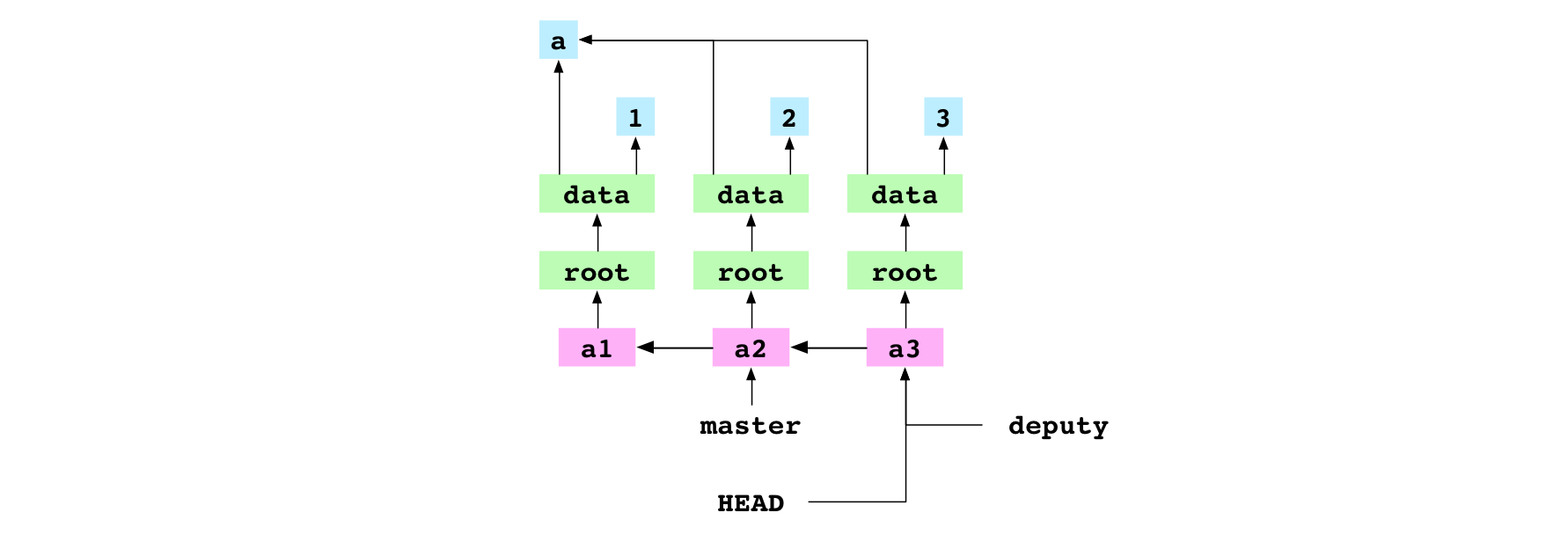
Image : Le commit a3, désormais sur la branche deputy
Basculer sur une branche
~/alpha $ git checkout master
Basculement sur la branche 'master'
L’utilisateur bascule sur la branche master.
Pour commencer, Git récupère le commit a2 vers lequel pointe la branche master puis il récupère le graphe sur lequel pointe le commit.
Ensuite, dans la copie de travail, Git écrit le contenu des fichiers qui sont listés dans le graphe. Ainsi, il écrit 2 dans le fichier data/number.txt.
Lors d’une troisième étape, Git écrit la liste des fichiers du graphe dans l’index. Dans l’index, l’élément pour le fichier data/number.txt pointe désormais vers l’empreinte du blob 2.
Enfin, Git fait pointer la référence HEAD sur master en modifiant son contenu :
ref: refs/heads/master
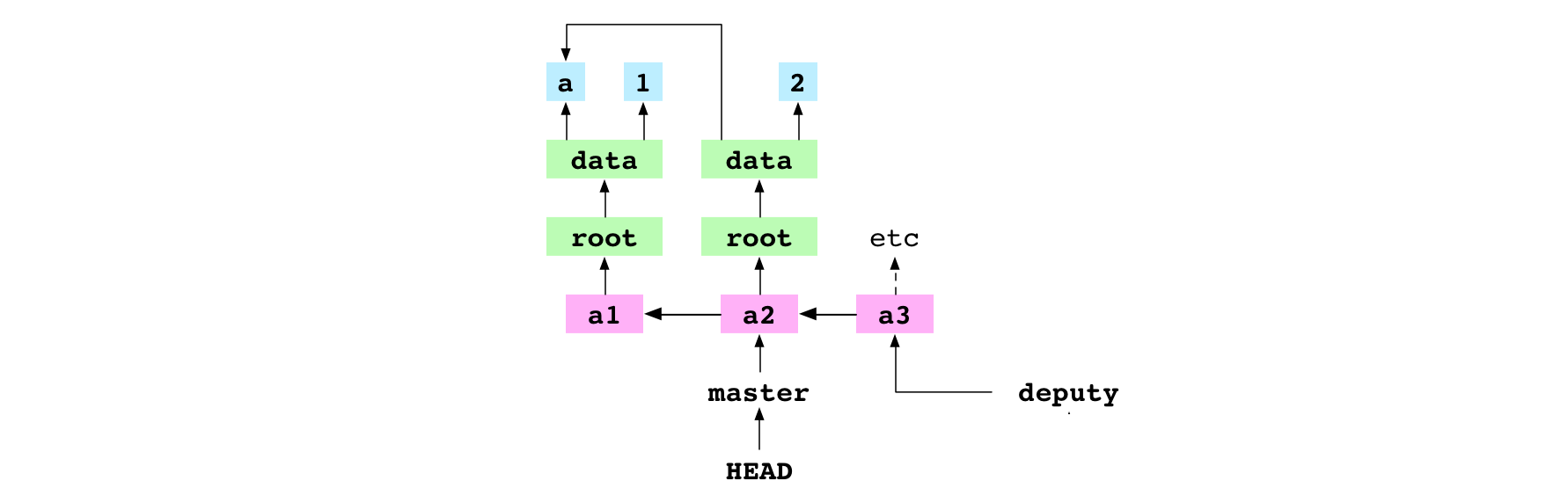
Image : Basculement sur master et pointage vers le commit a2
Basculer sur une branche incompatible avec la copie de travail
~/alpha $ printf '789' > data/number.txt
~/alpha $ git checkout deputy
Your local changes to the following files would be overwritten
by checkout:
data/number.txt
Commit your changes or stash them before you
switch branches.
L’utilisateur écrit par erreur 789 dans le fichier dans data/number.txt puis essaie de basculer sur la branche deputy. Git empêche le basculement.
La référence HEAD pointe sur la branche master qui pointe vers le commit a2 où data/number.txt contient 2. La branche deputy pointe vers le commit a3 où data/number.txt contient 3. Dans la copie de travail, data/number.txt contient 789. Toutes ces versions sont différentes et ces différences doivent être résolues.
Git pourrait remplacer la version du fichier data/number.txt de la copie de travail par celle qui correspond au commit sur lequel on bascule mais il empêche à tout prix de perdre des données.
Git pourrait fusionner la version de la copie de travail avec la version sur laquelle on bascule… mais c’est compliqué.
C’est pour ça que Git interrompt le basculement.
~/alpha $ printf '2' > data/number.txt
~/alpha $ git checkout deputy
Basculement sur la branche 'deputy'
L’utilisateur remarque qu’il a édité data/number.txt par accident puis réécrit 2 dans le fichier. Il peut alors basculer sans problème.
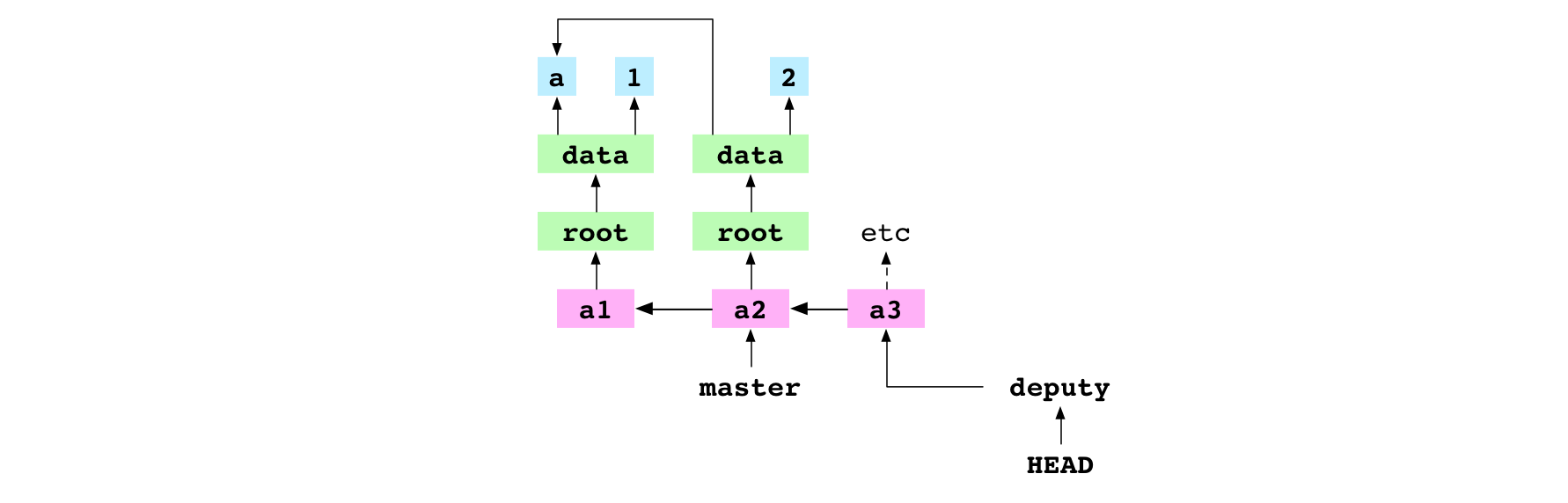
Image : Basculement sur deputy
Fusionner un commit qui est un ancêtre
~/alpha $ git merge master
Already up-to-date.
L’utilisateur fusionne la branche master sur la branche deputy. Fusionner deux branches signifie qu’on fusionne deux commits. Le premier commit est celui sur lequel pointe la branche deputy : c’est le commit receveur. Le deuxième commit est celui sur lequel point la branche master : c’est le commit donneur. Pour cette fusion, Git n’a rien à faire et c’est ce qu’il indique : Already up-to-date (déjà à jour).
Propriété du graphe : la succession de commits du graphe est interprétée comme une succession de modifications à appliquer au contenu du dépôt. Cela signifie que, lors d’une fusion, si le commit donneur est un ancêtre du commit receveur, Git n’a rien à faire : les modifications concernées ont déjà été intégrées au dépôt.
Fusionner un commit qui est un descendant
~/alpha $ git checkout master
Basculement sur la branche 'master'
L’utilisateur bascule sur la branche master.
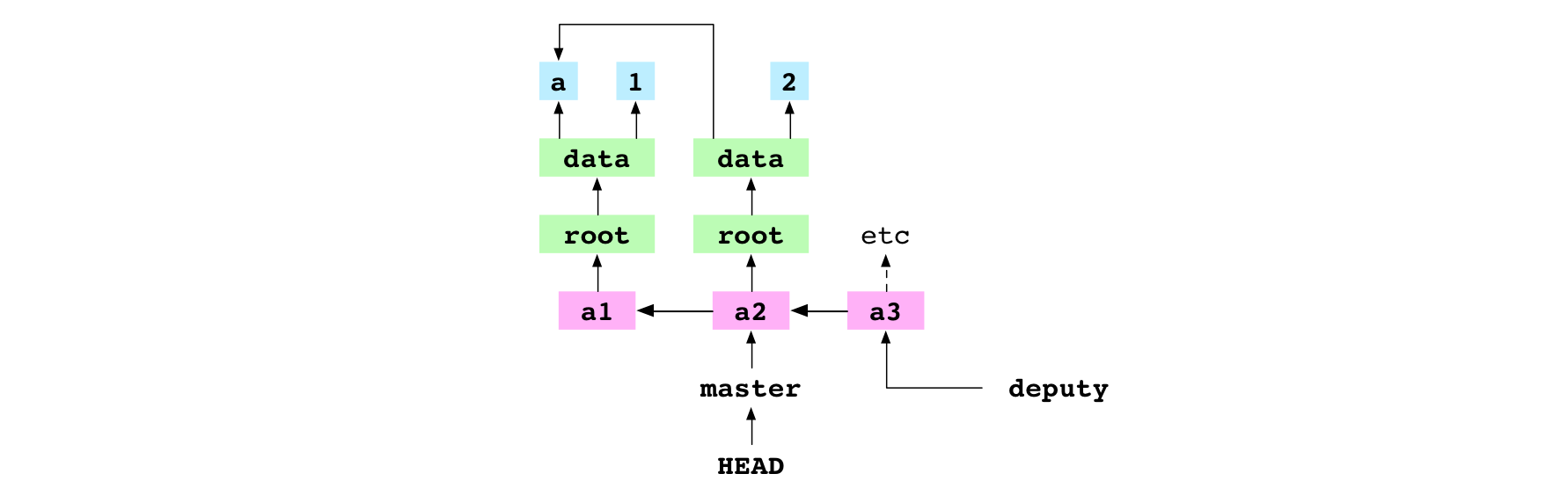
Image : Basculement sur master qui pointe sur le commit a2
~/alpha $ git merge deputy
Fast-forward
Grâce à cette commande, l’utilisateur fusionne la branche deputy avec la branche master. Git analyse et comprend que le commit receveur, a2, est un ancêtre du commit donneur, a3. Il peut donc appliquer une fusion en avance rapide (fast-forward merge).
Git récupère le commit donneur et l’arbre correspondant. Il écrit les fichiers du graphe dans la copie de travail et dans l’index puis effectue une avance rapide pour pointer sur le commit a3.
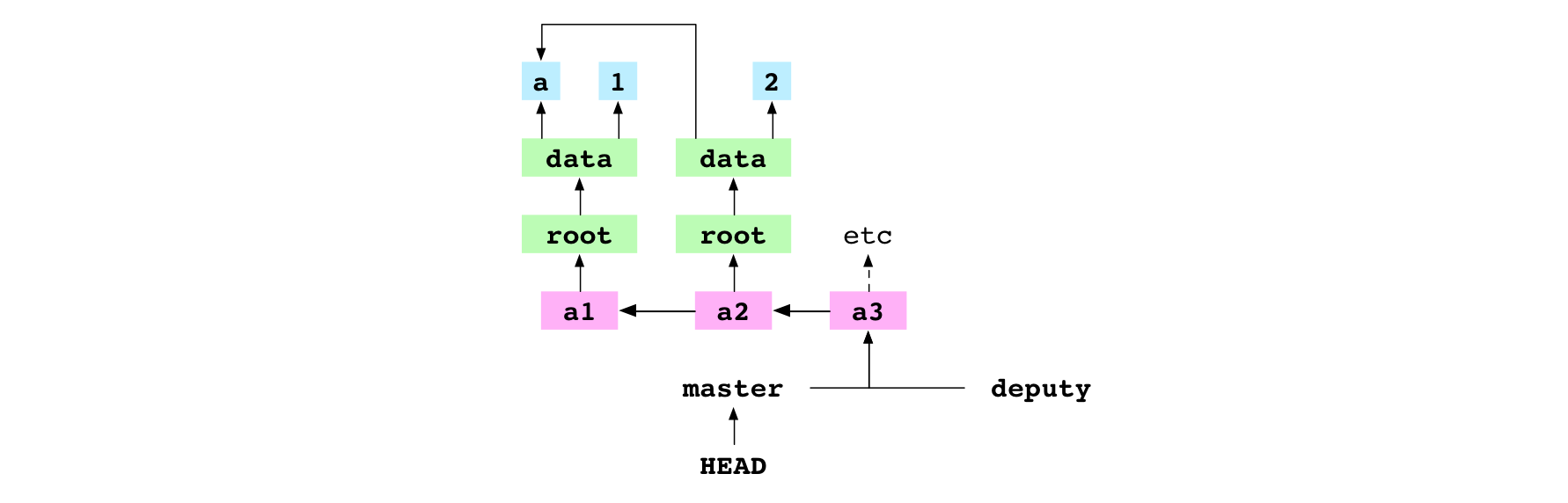
Image : Le commit a3 de la branche deputy, fusionné en avance rapide sur la branche master
Propriété du graphe : les suites de commits du graphe sont interprétées comme une suite de modifications appliquées sur le contenu du dépôt. Cela signifie que pendant une fusion, si le commit donneur est un descendant du commit receveur, l’historique n’est pas modifié. Il existe déjà une succession de commits qui décrit les modifications à réaliser : ce sont les commits situés entre le commit receveur et le commit donneur. Toutefois, si l’historique Git ne change pas, le graphe Git, lui, change. La référence concrète vers laquelle pointe HEAD est mise à jour pour correspondre au commit donneur.
Fusionner deux commits ayant des historiques différents
~/alpha $ printf '4' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'a4'
[master 7b7bd9a] a4
L’utilisateur écrit 4 dans le fichier number.txt puis ajoute un commit pour cette modification sur la branche master.
~/alpha $ git checkout deputy
Basculement sur la branche 'deputy'
~/alpha $ printf 'b' > data/letter.txt
~/alpha $ git add data/letter.txt
~/alpha $ git commit -m 'b3'
[deputy 982dffb] b3
Avec ces instructions, l’utilisateur bascule sur la branche deputy puis écrit b dans le fichier data/letter.txt et ajoute un commit pour cette modification sur la branche deputy.
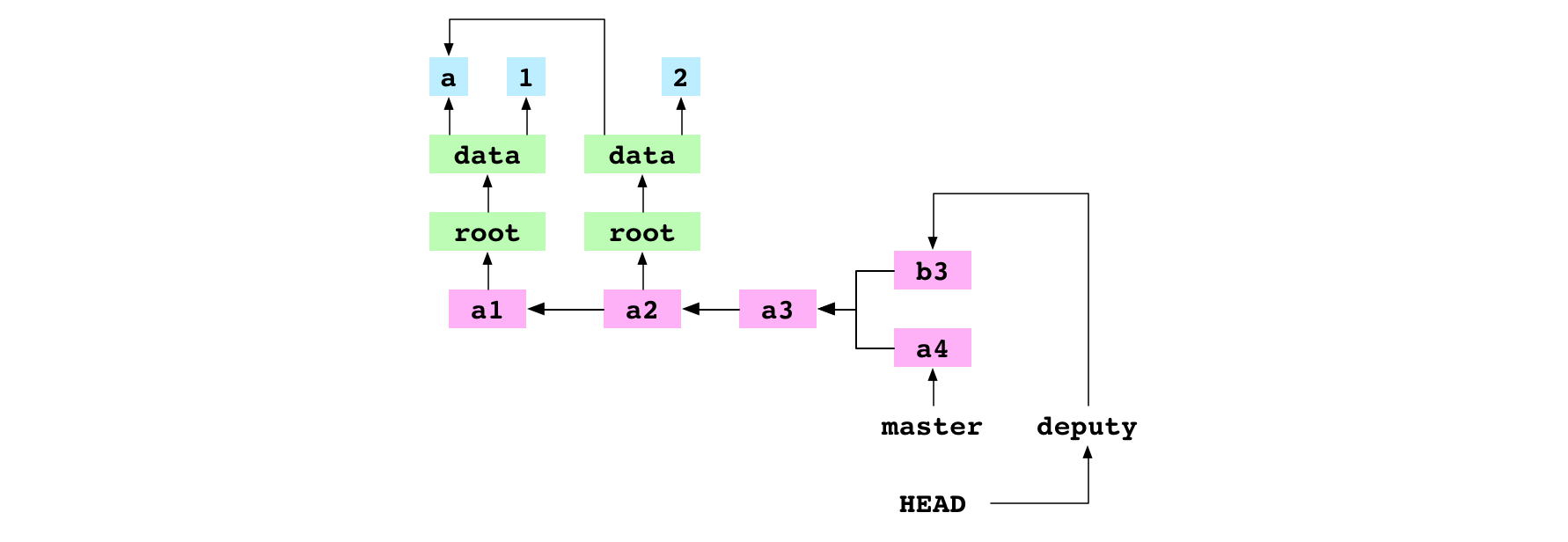
Image : Le commit a4 appliqué sur master, le commit b3 ajouté sur deputy et le basculement sur deputy.
Propriété du graphe : les commits peuvent partager un même parent. Cela signifie que de nouveaux historiques peuvent être créés.
Propriété du graphe : un commit peut avoir plusieurs parents. Cela signifie que deux historiques peuvent être fusionnés par un commit qui possède deux parents, c’est ce qu’on appelle un commit de fusion.
~/alpha $ git merge master -m 'b4'
Merge made by the 'recursive' strategy.
Ici, l’utilisateur fusionne la branche master avec la branche deputy.
Git découvre que le commit receveur, b3 et que le commit donneur, a4, ont chacun un historique différent. Il crée un commit de fusion. Ce processus se déroule selon huit étapes.
Tout d’abord, Git écrit l’empreinte du commit donneur dans le fichier alpha/.git/MERGE_HEAD. Ce fichier, lorsqu’il existe, indique que Git est en train d’effectuer une fusion.
Ensuite, Git détermine le commit de base : c’est le plus proche ancêtre commun au commit donneur et au commit receveur.
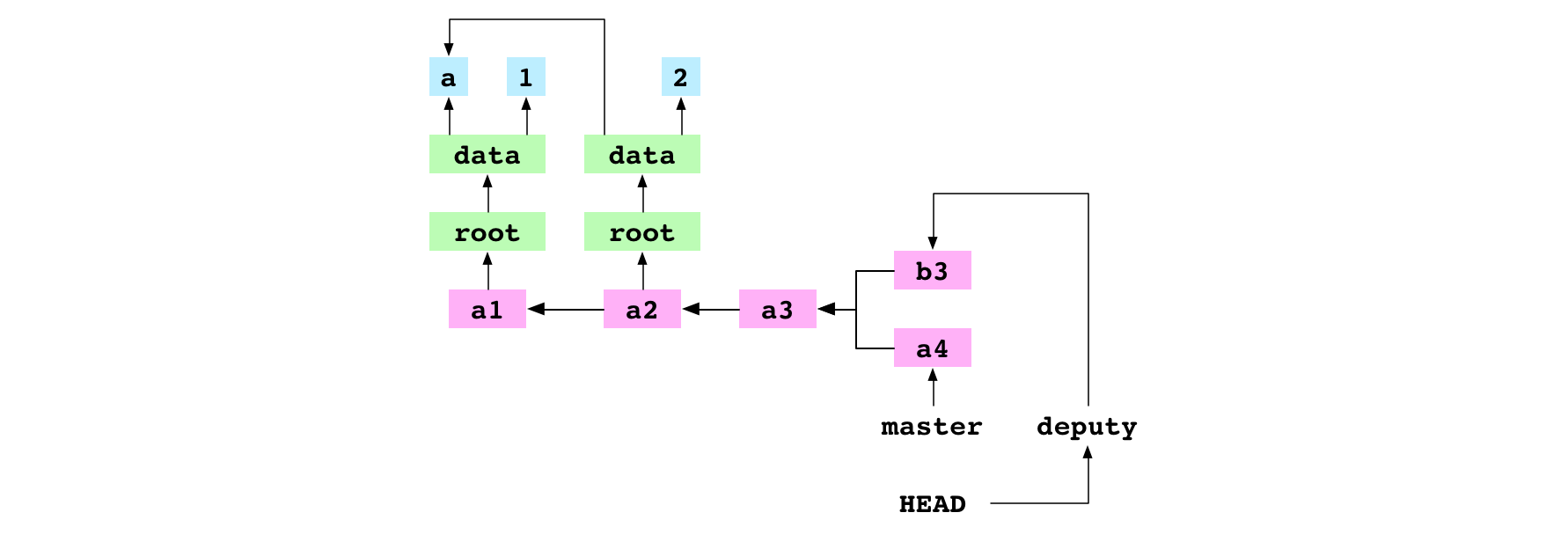
Image : a3, le commit de base pour a4 et b3
Propriété du graphe : les commits ont des parents. Cela signifie qu’on peut déterminer le point à partir duquel deux historiques ont divergé. Git remonte l’historique de b3 pour trouver ses ancêtres et fait de même avec a4 pour trouver les ancêtres de a4. Il trouve alors l’ancêtre le plus récent, présent dans les deux historiques : a3. Ce commit est le commit de base.
Dans un troisième temps, Git génère trois index pour le commit de base, le commit donneur et le commit receveur grâce à leurs graphes respectifs.
Lors de la quatrième étape, Git génère une différence qui combine les modifications appliquées à la base par le commit receveur d’une part et le commit donneur d’autre part. Cette différence est une liste de chemins de fichiers qui identifient un changement : un ajout, une suppression, une modification ou un conflit.
Pour la construire, Git dresse la liste de tous les fichiers qui apparaissent dans les index du commit de base, du commit receveur et du commit donneur. Pour chacune, il compare les éléments de l’index pour choisir le changement à appliquer au fichier et il écrit l’élément correspondant dans la différence. Dans cet exemple, la différence possède deux éléments.
Le premier élément concerne data/letter.txt. Le contenu de ce fichier vaut a pour le commit de base, b pour le commit receveur et a pour le commit donneur. Le contenu est donc différent entre la base et le receveur mais est le même entre la base et le donneur. Git détecte que le contenu a été modifié par le receveur mais pas par le donneur. Aussi, l’élément de la liste des différences pour data/letter.txt est une modification (ce n’est pas un conflit).
Le deuxième élément se rapporte à data/number.txt. Dans ce cas, le contenu est le même entre la base et le receveur et il est différent dans le donneur. L’élément de la liste des différences pour le fichier data/letter.txt est également une modification.
Propriété du graphe : il est possible de déterminer le commit de base d’une fusion. Cela signifie que si un fichier a évolué depuis le commit de base mais uniquement sur le receveur ou sur le donneur, Git peut automatiquement résoudre la fusion pour ce fichier. Cela diminue le travail laissé à l’utilisateur.
Cinquièmement, les modifications indiquées dans la liste des différences (diff) sont appliquées sur la copie de travail. Le contenu de data/letter.txt vaut désormais b et le contenu de data/number.txt vaut désormais 4.
Sixièmement, les modifications indiquées dans la liste des différences sont appliquées à l’index. L’entrée pour data/letter.txt pointe désormais vers le blob b et l’entrée pour data/number.txt pointe désormais vers le blob 4.
Septièmement, l’index mis à jour est commité :
tree 20294508aea3fb6f05fcc49adaecc2e6d60f7e7d
parent 982dffb20f8d6a25a8554cc8d765fb9f3ff1333b
parent 7b7bd9a5253f47360d5787095afc5ba56591bfe7
author Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500
committer Mary Rose Cook <mary@maryrosecook.com> 1425596551 -0500
b4
On peut remarquer ici que le commit possède deux parents.
À la huitième et dernière étape, Git fait pointer la branche courante, deputy, sur le nouveau commit.
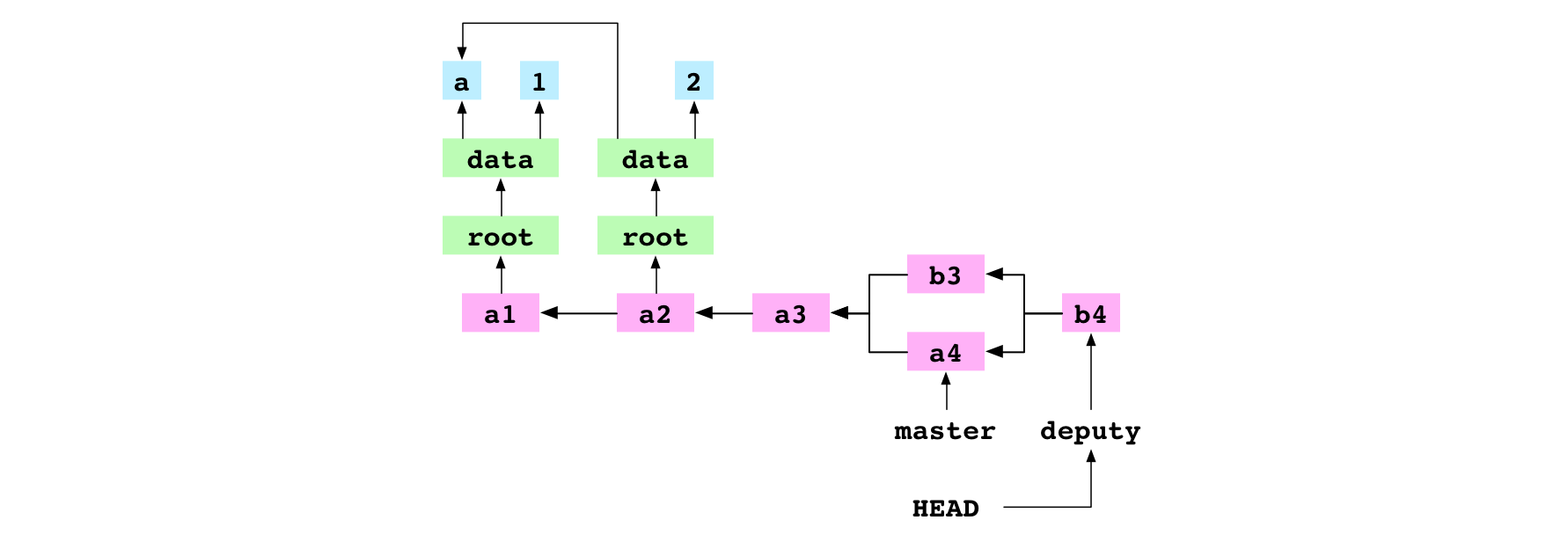
Image : b4, le commit de fusion obtenu suite à la fusion récursive de a4 sur b3
Fusionner deux commits ayant un historique différent et qui modifient le même fichier
~/alpha $ git checkout master
Basculement sur la branche 'master'
~/alpha $ git merge deputy
Fast-forward
L’utilisateur bascule sur la branche master puis fusionne la branche master. Cela propage la branche master en avance rapide jusqu’au commit b4. Les branches master et deputy pointent désormais vers le même commit.
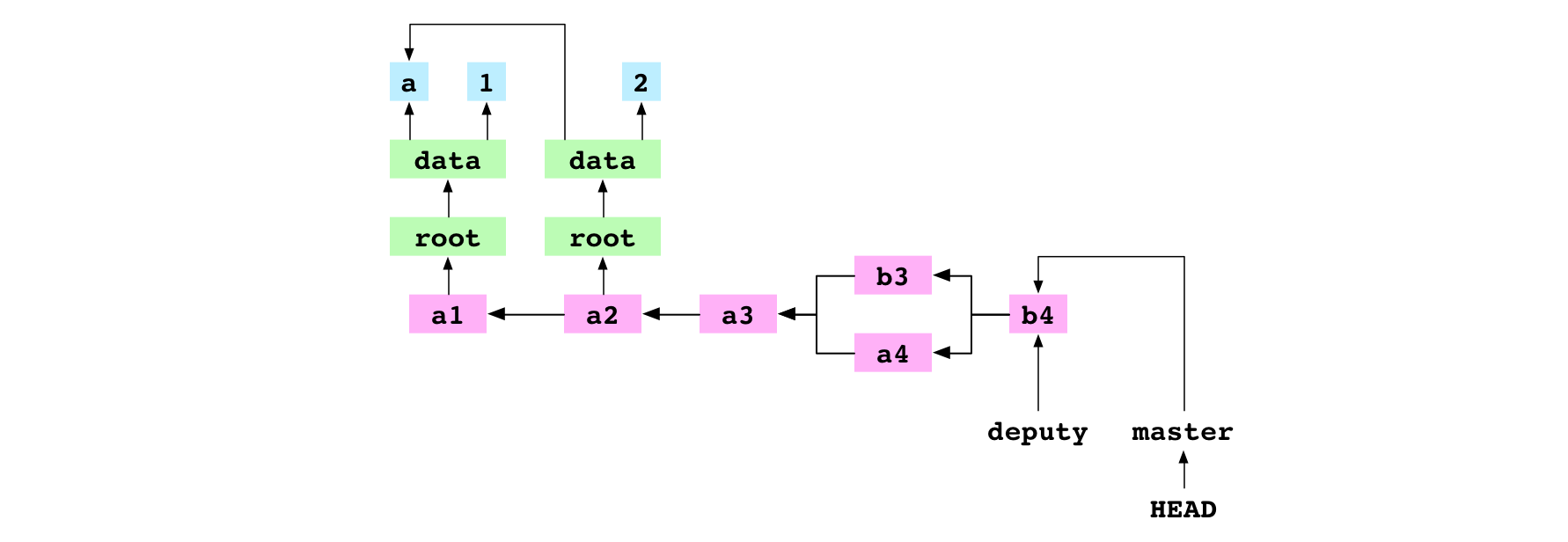
Image : La branche deputy, fusionnée avec master permet d’amener master au dernier commit, b4.
~/alpha $ git checkout deputy
Basculement sur la branche 'deputy'
~/alpha $ printf '5' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b5'
[deputy bd797c2] b5
L’utilisateur bascule sur la branche deputy puis ajoute un fichier data/number.txt qui contient 5 et ajoute un commit sur deputy pour enregistrer cette modification.
~/alpha $ git checkout master
Basculement sur la branche 'master'
~/alpha $ printf '6' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m 'b6'
[master 4c3ce18] b6
L’utilisateur bascule sur master. Il définit un fichier data/number.txt qui contient 6 et ajoute un commit sur master pour cette modification.
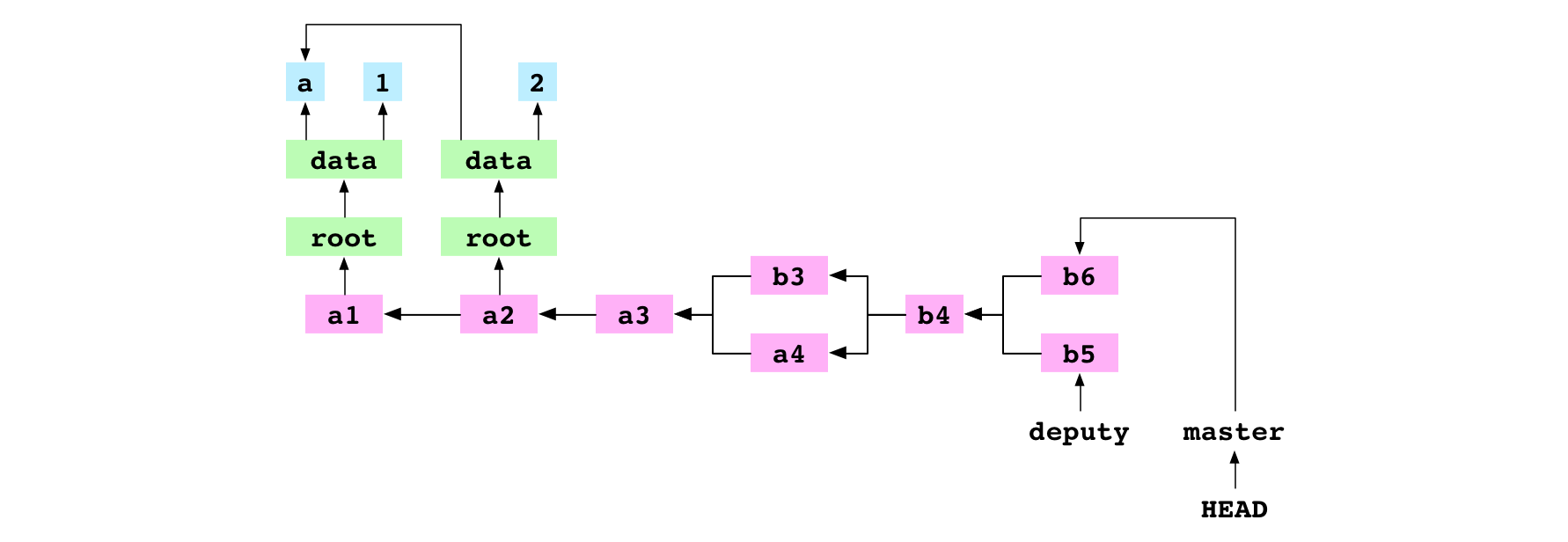
Image : Le commit b5 sur deputy et le commit b6 sur master.
~/alpha $ git merge deputy
CONFLIT (contenu) : Conflit de fusion dans data/number.txt
La fusion automatique a échoué ; réglez les conflits et validez le résultat.
L’utilisateur fusionne deputy et master. Il y a un conflit et la fusion est donc interrompue. Lorsqu’un conflit se produit, les 6 premières étapes sont les mêmes que lors d’une fusion sans conflit : on définit .git/MERGE_HEAD, on trouve le commit de base, on génère les index de la base, les commits donneurs et receveurs, on crée un diff, on met à jour la copie de travail et l’index. Étant donné le conflit, la septième étape de commit et la huitième qui met à jour la référence n’ont jamais lieu. Revoyons les étapes pour voir ce qui se passe exactement.
Pour commencer, Git écrit l’empreinte du commit donneur dans un fichier .git/MERGE_HEAD.
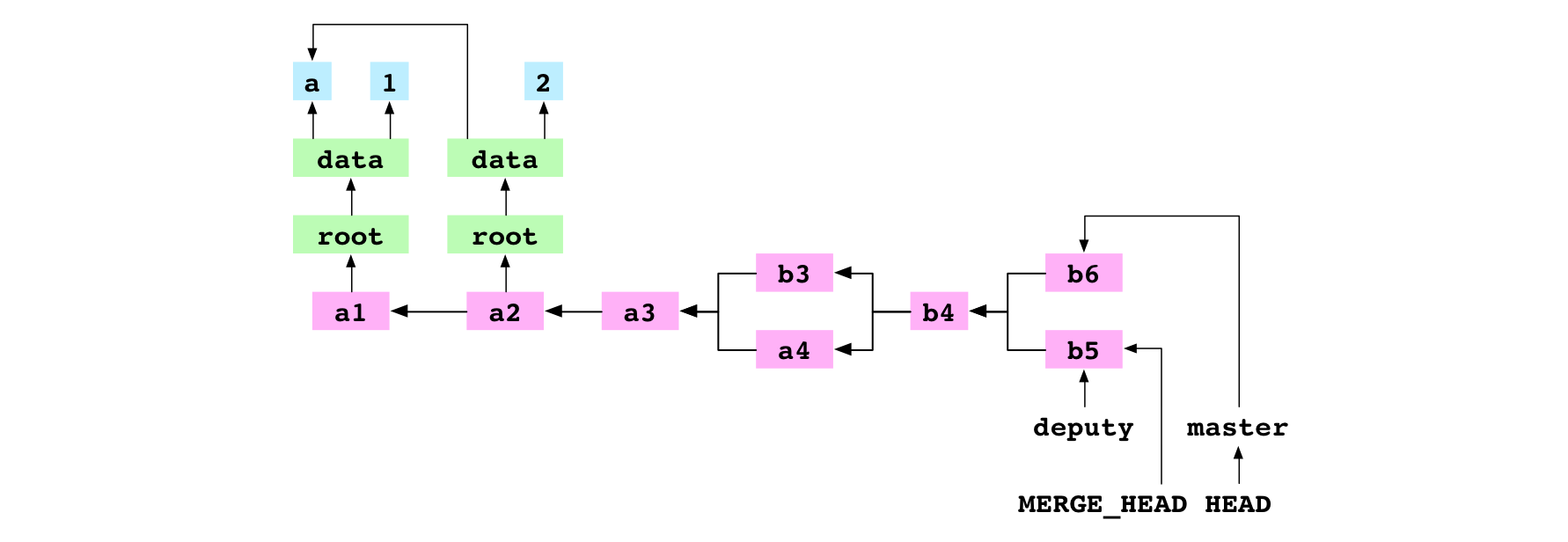
_Image : L’écriture de MERGE_HEAD lors de la fusion de b5 sur b6_
Ensuite, Git identifie le commit de base : b4.
Lors de la troisième étape, Git génère les index pour le commit de base, le commit donneur et le commit receveur.
À la quatrième étape, Git génère une différence (diff) qui combine les modifications appliquées à la base par le commit receveur d’une part et par le commit donner d’autre part. Cette différence est une liste de chemins de fichiers qui traduisent un changement : un ajout, une suppression, une modification ou un conflit.
Dans notre cas, la différence ne contient qu’un seul élément : data/number.txt. Cet élément est identifié comme un conflit car le contenu de data/number.txt est différent entre le receveur, le donneur et la base.
Ensuite, à la cinquième étape, les modifications indiquées pour chacun des éléments de la différence sont appliquées à la copie de travail. Lorsqu’il s’agit d’un conflit, Git écrit les deux versions du fichier dans la copie de travail. Le contenu de data/number.txt vaut alors :
<<<<<<< HEAD
6
=======
5
>>>>>>> deputy
À la sixième étape, les modifications listées pour les éléments de la différence sont appliquées à l’index. Les éléments de l’index sont identifiés de façon unique grâce à une combinaison de leur chemin et de leur niveau. Le niveau correspondant à un fichier sans conflit est 0. Avant cette fusion, l’index ressemblait à ceci, les 0 correspondant aux niveaux :
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb
Après l’écriture de la différence relative à la fusion dans l’index, l’index ressemble à ceci :
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
1 data/number.txt bf0d87ab1b2b0ec1a11a3973d2845b42413d9767
2 data/number.txt 62f9457511f879886bb7728c986fe10b0ece6bcb
3 data/number.txt 7813681f5b41c028345ca62a2be376bae70b7f61
L’élément pour data/letter.txt de niveau 0 est le même qu’avant la fusion. Il n’y a plus d’élément data/number.txt de niveau 0 mais trois nouveaux éléments à la place. L’élément de niveau 1 contient l’empreinte du contenu de data/number.txt pour le commit de base. L’élément de niveau 2 contient l’empreinte du contenu de data/number.txt pour le commit receveur. Celui de niveau trois contient l’empreinte du contenu de data/number.txt pour le commit donneur. La présence de ces trois éléments permet à Git d’identifier un conflit pour le fichier data/number.txt.
Le processus de merge s’arrête.
~/alpha $ printf '11' > data/number.txt
~/alpha $ git add data/number.txt
Ici l’utilisateur intègre le contenu des deux versions conflictuelles en écrivant 11 dans data/number.txt. Ensuite, il ajoute le fichier à l’index. Git ajoute un blob qui contient 11. L’ajout d’un fichier en conflit indique à Git que le conflit est résolu. Aussi, Git retire les éléments de niveaux 1, 2 et 3 dans l’index qu’il remplace par une nouvelle ligne de niveau 0 contenant l’empreinte du nouveau blob. L’index contient désormais les lignes suivantes :
0 data/letter.txt 63d8dbd40c23542e740659a7168a0ce3138ea748
0 data/number.txt 9d607966b721abde8931ddd052181fae905db503
~/alpha $ git commit -m 'b11'
[master 251a513] b11
Lors de la septième étape, l’utilisateur ajoute un commit. Git voit le fichier .git/MERGE_HEAD dans le dépôt et sait donc qu’une fusion est en cours. Il vérifie l’index et ne trouve aucun conflit, il crée alors un nouveau commit, b11, pour enregistrer le contenu de la fusion pour laquelle le conflit a été résolu. Il supprime le fichier .git/MERGE_HEAD. La fusion est alors terminée.
Enfin, à la huitième étape, Git fait pointer la branche courante, master, sur le dernier commit.
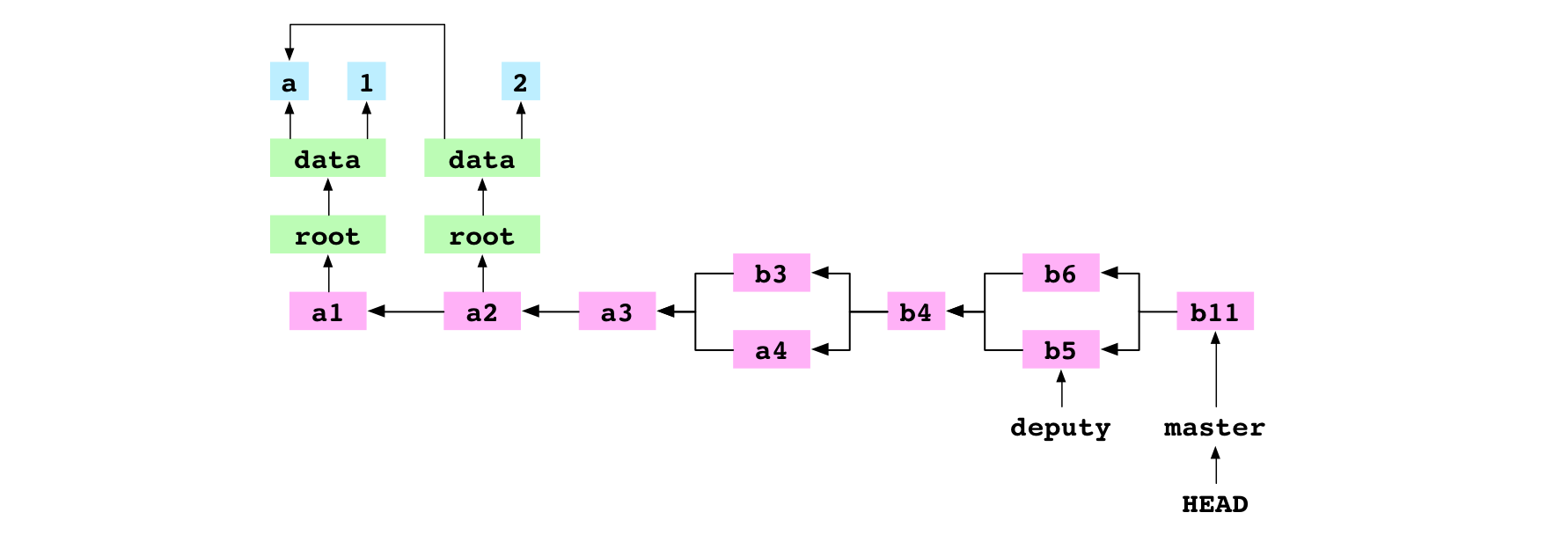
Image : b11, le commit de fusion provenant de la fusion récursive conflictuelle entre b5 et b6
Supprimer un fichier
Le diagramme de ce graphe Git contient l’historique des commits, les arbres et les blobs du dernier commit, ainsi que la copie de travail et l’index :
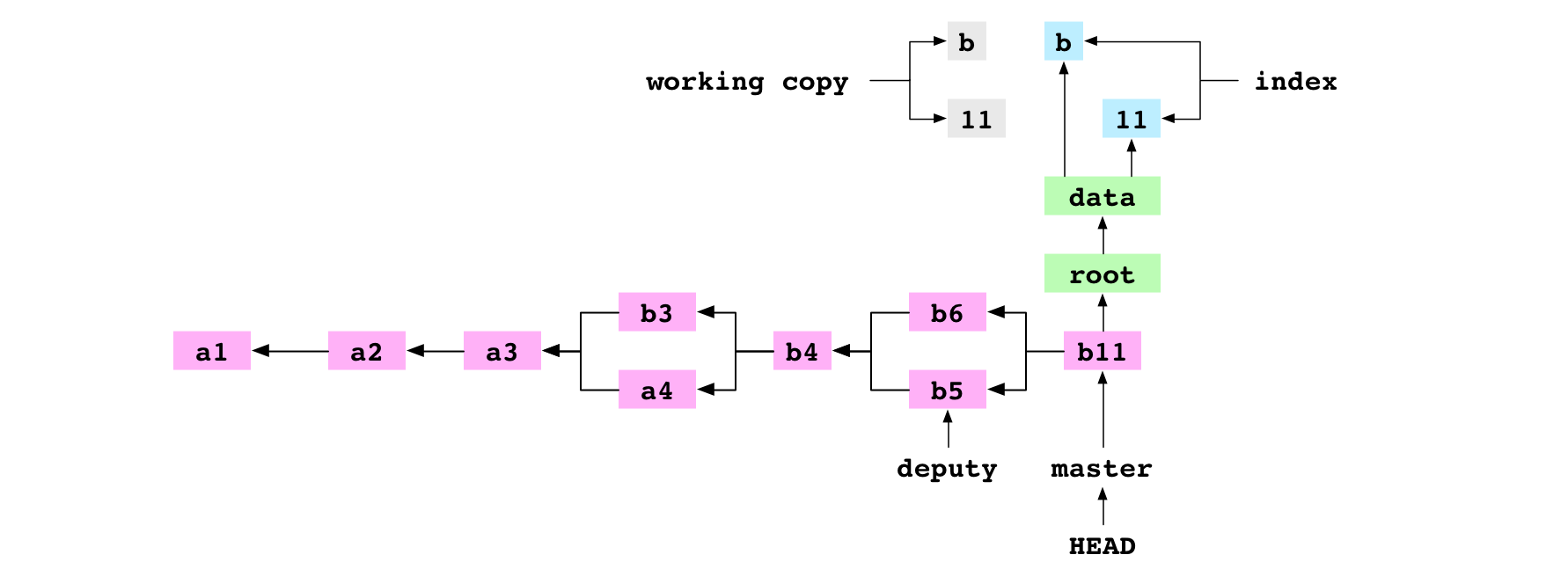
Image : La copie de travail, l’index, le commit b11 et son graphe
~/alpha $ git rm data/letter.txt
rm 'data/letter.txt'
L’utilisateur indique à Git de supprimer data/letter.txt. Le fichier est supprimé de la copie de travail et l’entrée est supprimée de l’index.
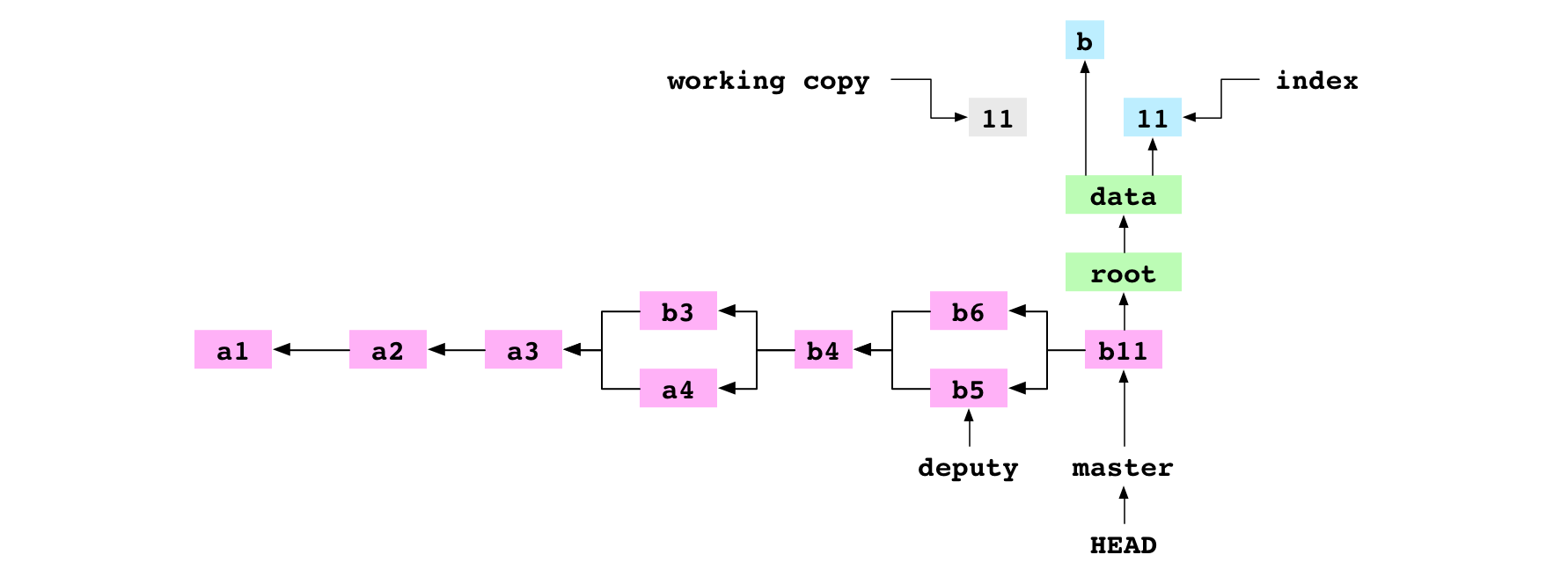
Image : L’état après la suppression de data/letter.txt de la copie de travail et de l’index.
~/alpha $ git commit -m '11'
[master d14c7d2] 11
L’utilisateur ajoute un commit. Comme toujours avec le commit, Git construit l’arbre qui représente le contenu de l’index. data/letter.txt n’est pas inclus dans cet arbre car il n’est pas dans l’index.
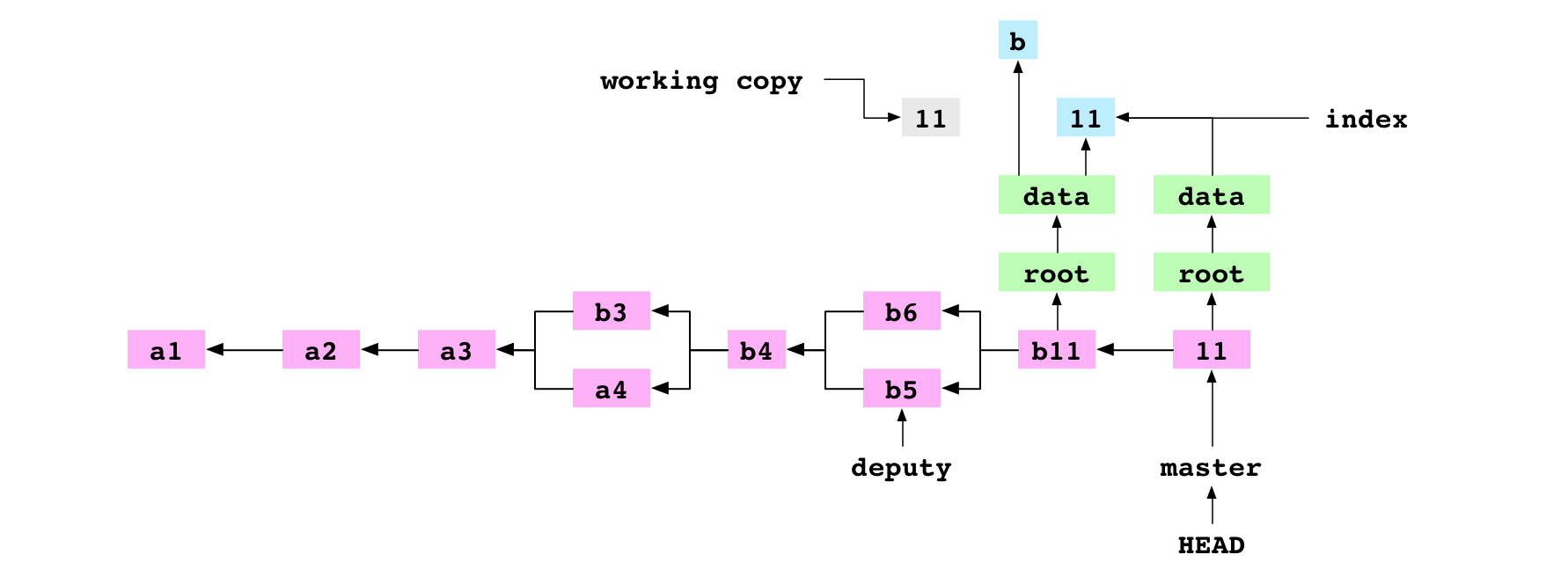
Image : Le commit 11 réalisé après la suppression de data/letter.txt
Copier un dépôt
~/alpha $ cd ..
~ $ cp -R alpha bravo
L’utilisateur copie le contenu du répertoire alpha/ dans le répertoire bravo/. On obtient alors l’arborescence de fichiers suivante :
~
├── alpha
| └── data
| └── number.txt
└── bravo
└── data
└── number.txt
Il y a désormais un autre graphe Git dans le répertoire bravo :
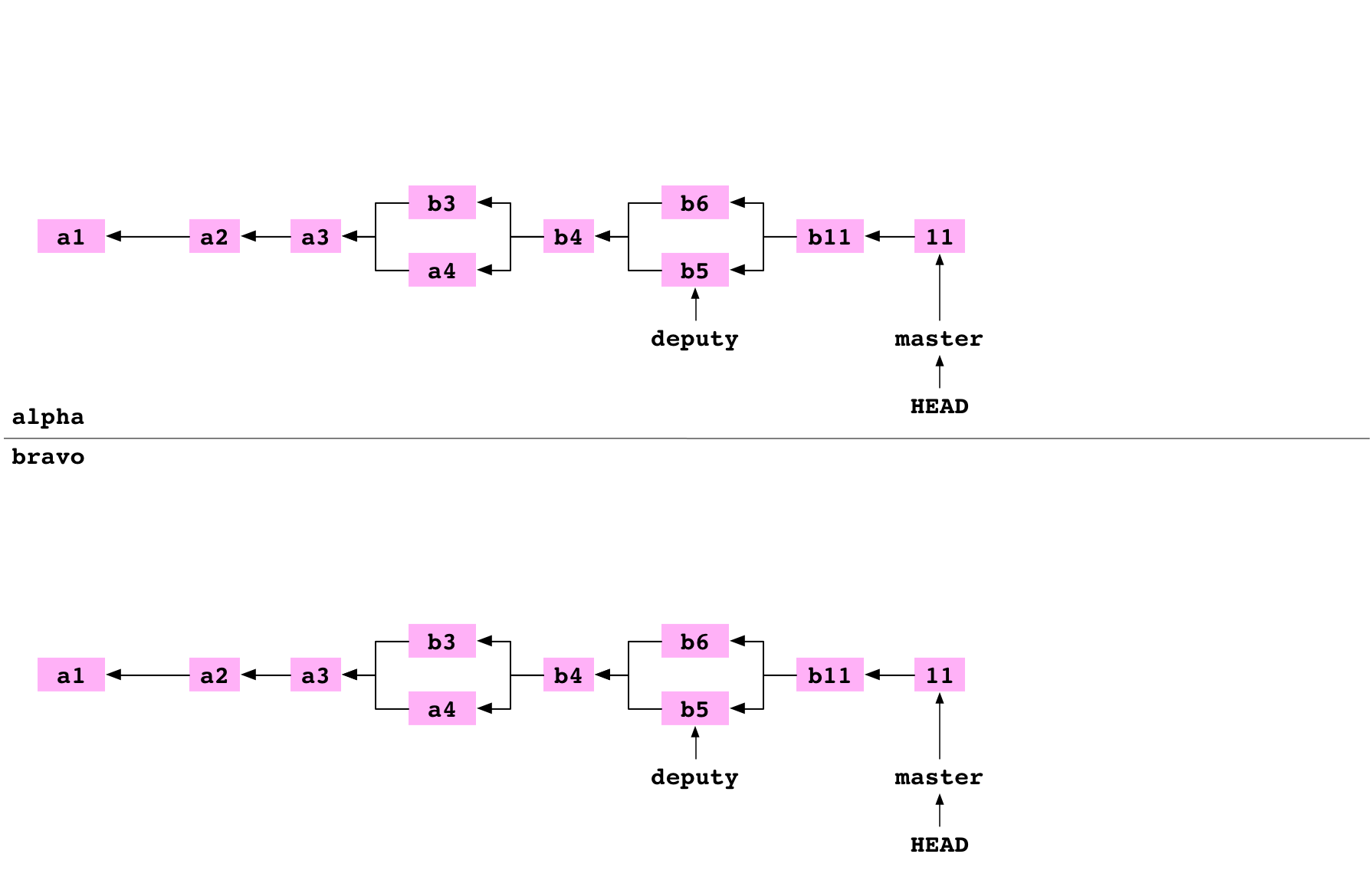
Image : Le nouveau graphe créé lorsqu’alpha est copié en bravo avec cp
Lier un dépôt à un autre dépôt
~ $ cd alpha
~/alpha $ git remote add bravo ../bravo
L’utilisateur retourne dans le dépôt alpha. Ensuite, il définit bravo, un dépôt distant de alpha. Cette opération ajoute les lignes suivantes au fichier alpha/.git/config :
[remote "bravo"]
url = ../bravo/
Ces lignes signifient qu’il y a un dépôt distant appelé bravo et que celui-ci se situe à l’emplacement ../bravo.
Récupérer une branche depuis un dépôt distant
~/alpha $ cd ../bravo
~/bravo $ printf '12' > data/number.txt
~/bravo $ git add data/number.txt
~/bravo $ git commit -m '12'
[master 94cd04d] 12
L’utilisateur se déplace dans le dépôt bravo puis crée un fichier data/number.txt qui contient 12 puis ajoute un commit pour cette modification sur la branche master de bravo.
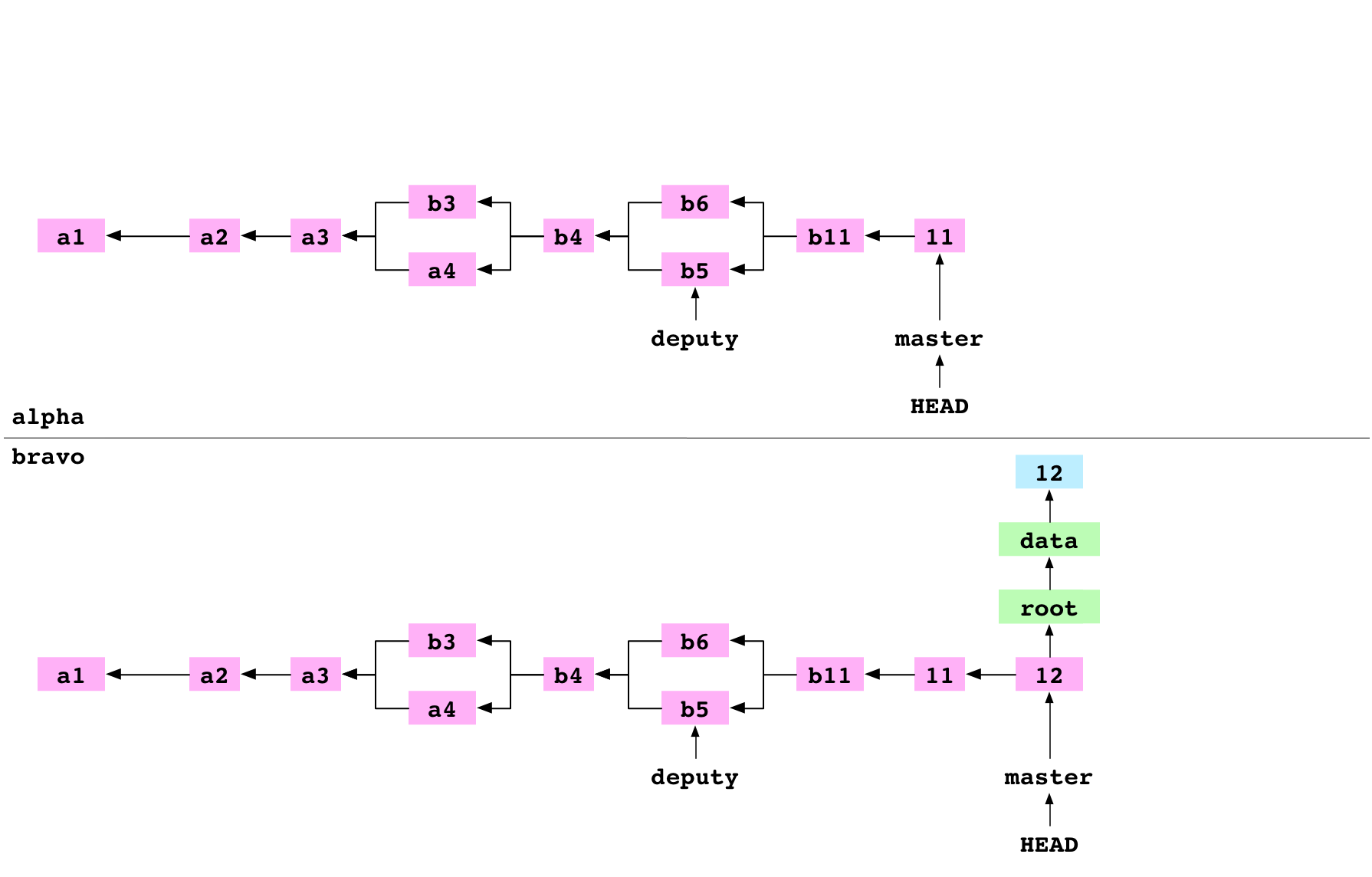
Image : Le commit 12 sur le dépôt bravo
~/bravo $ cd ../alpha
~/alpha $ git fetch bravo master
Dépaquetage des objets : 100%
Depuis ../bravo
* branch master -> FETCH_HEAD
L’utilisateur se déplace dans le dépôt alpha. Il récupère ensuite la branche master depuis le dépôt bravo vers alpha. Cette récupération se fait en quatre étapes.
Pour commencer, Git récupère l’empreinte (hash) du commit sur lequel pointe la branche master du dépôt bravo. C’est l’empreinte du commit 12.
Ensuite, Git dresse la liste de tous les objets dont dépend le commit 12 : l’objet même qui décrit le commit, les objets qui sont sur son graphe, les commits ancêtres du commit 12 et les objets qui sont dans leurs graphes. Il retire alors de cette liste tous les objets déjà contenus dans la base de données des objets de alpha. Ce qui reste est copié dans alpha/.git/objects/.
La troisième étape consiste à modifier le fichier de référence alpha/.git/refs/remotes/bravo/master afin qu’il contienne l’empreinte du commit 12.
Enfin, le contenu de alpha/.git/FETCH_HEAD est défini avec :
94cd04d93ae88a1f53a4646532b1e8cdfbc0977f branch 'master' of ../bravo
Cette ligne indique que la commande fetch la plus récente a récupéré le commit 12 de la branche master depuis bravo.
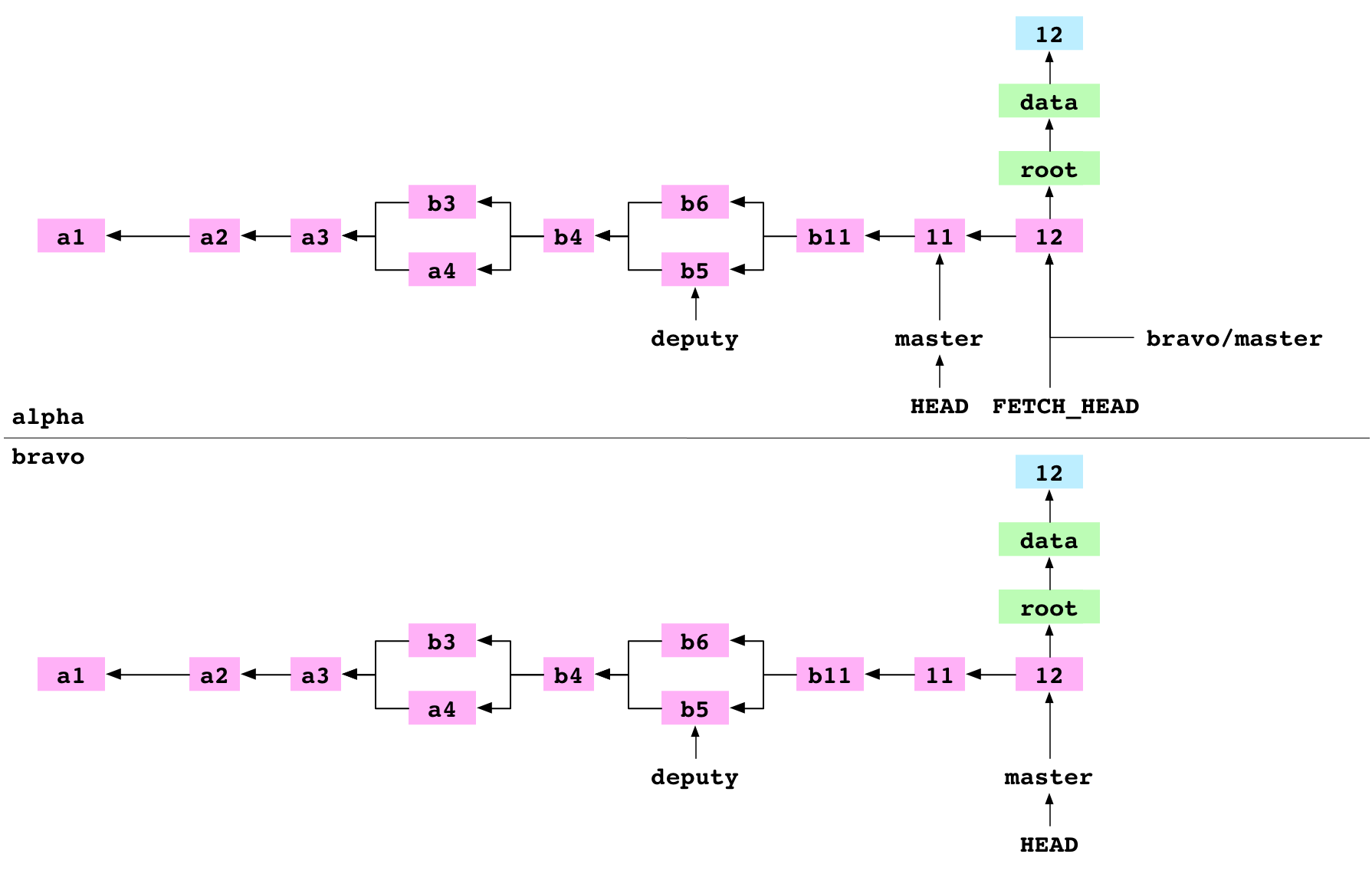
Image : alpha après avoir récupéré bravo/master
Propriété de graphe : les objets peuvent être copiés. Cela veut dire que l’historique peut être partagé entre les dépôts.
Propriété de graphe : un dépôt peut stocker des références à des branches distantes comme alpha/.git/refs/remotes/bravo/master. Cela veut dire qu’un dépôt peut enregistrer localement l’état d’une branche ou d’un dépôt distant. C’est valable au moment où on le récupère mais ça sera périmé quand la branche distante changera.
Fusionner FETCH_HEAD
~/alpha $ git merge FETCH_HEAD
Mise à jour d14c7d2..94cd04d
Fast-forward
L’utilisateur fusionne FETCH_HEAD. FETCH_HEAD est simplement une autre référence. Elle correspond ici au commit 12, celui qui est donné. La référence HEAD correspond au commit 11, celui qui reçoit. Git fait une fusion en avance rapide (fast-forward merge) et fait pointer la branche master sur le commit 12.
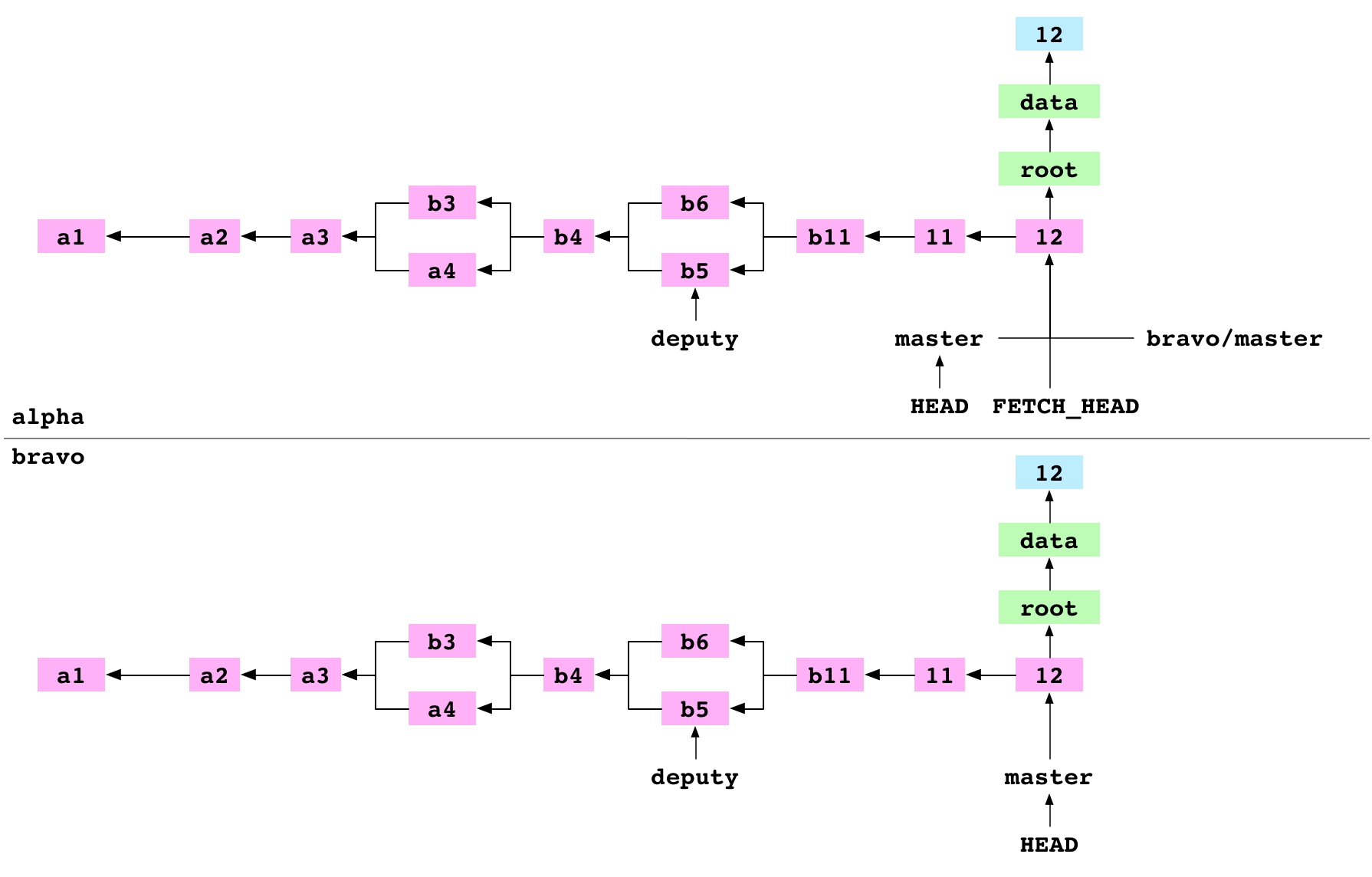
_Image : Le dépôt alpha après la fusion avec FETCH_HEAD_
Tirer une branche depuis un dépôt distant
~/alpha $ git pull bravo master
Already up-to-date.
Ici, l’utilisateur tire la branche master depuis le dépôt bravo vers le dépôt alpha. pull est un raccourci pour « récupère puis fusionne FETCH_HEAD » (fetch/merge). Git applique ces deux commandes puis indique que la branche master est déjà à jour.
Cloner un dépôt
~/alpha $ cd ..
~ $ git clone alpha charlie
Clonage dans 'charlie'
Là, l’utilisateur remonte dans le dossier parent puis clone le dédpôt alpha vers un dépôt charlie. Cloner le dépôt vers charlie permet d’obtenir des résultats similaires à la copie (via cp) utilisée pour créer le dépôt bravo. Ici, Git crée un nouveau répertoire appelé charlie. Il initialise ce dossier en tant que dépôt Git puis ajoute alpha comme un dépôt distant, appelé origin. Il récupère (fetch) le contenu de origin puis fusionne FETCH_HEAD.
Pousser une branche vers une branche distante utilisée
~ $ cd alpha
~/alpha $ printf '13' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '13'
[master 3238468] 13
L’utilisateur retourne dans le dépôt alpha, ajoute un fichier data/number.txt qui contient 13 puis ajoute un commit pour cette modification sur la branche master sur le dépôt alpha.
~/alpha $ git remote add charlie ../charlie
Ensuite, il ajoute un dépôt charlie qui est un dépôt distant d’alpha.
~/alpha $ git push charlie master
Écriture des objets : 100%
remote error: refusing to update checked out
branch: refs/heads/master because it will make
the index and work tree inconsistent
Enfin, il pousse la branche master vers charlie.
Tous les objets nécessaires au commit 13 sont copiés dans charlie.
À cette étape, le push s’arrête. Git, comme à son habitude, indique à l’utilisateur qu’il y a un problème. Il refuse de pousser vers une branche utilisée sur le dépôt distant. C’est plutôt logique, une opération push mettrait à jour l’index du dépôt distant et son commit HEAD. Cette modification serait source de confusion si quelqu’un éditait la version de travail sur le dépôt distant.
Ici, l’utilisateur, pourrait créer une nouvelle branche, fusionner ce commit 13 sur cette branche puis pousser cette branche vers le dépôt charlie. En fait, ce qu’il veut, c’est un dépôt vers lequel pousser à tout moment, un dépôt central vers lequel on peut pousser ou depuis lequel on peut tirer des branches, sans personne qui n’y ajoute de commits directement. Bref, il veut quelque chose qui se comporte comme GitHub : c’est ce qu’on appelle un dépôt nu (bare).
Cloner un dépôt nu
~/alpha $ cd ..
~ $ git clone alpha delta --bare
Clonage dans le dépôt nu 'delta'
Ici, l’utilisateur se déplace dans le répertoire parent. Ensuite, il clone le dépôt alpha dans un dépôt delta, indiqué comme un dépôt nu (bare repository). C’est un clone classique avec deux différences notables : le fichier de configuration indique que le dépôt est un dépôt nu et les fichiers normalement stockés dans le dossier .git sont ici stocké à la racine du répertoire :
delta
├── HEAD
├── config
├── objects
└── refs
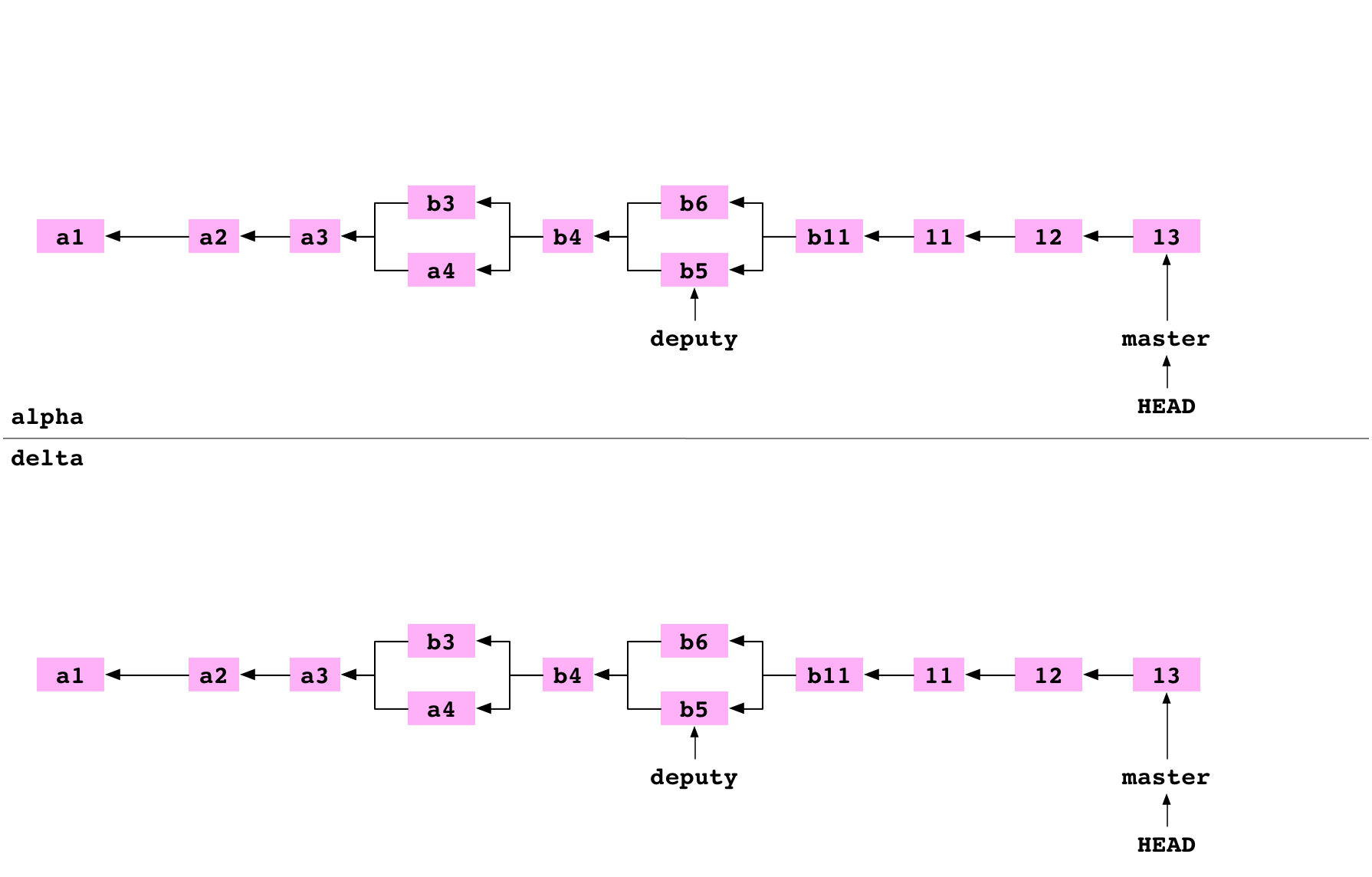
Image : Les graphes d’alpha et de delta après le clonage dans delta
Pousser une branche vers un dépôt nu
~ $ cd alpha
~/alpha $ git remote add delta ../delta
L’utilisateur retourne dans le dépôt alpha puis définit delta comme un dépôt distant sur alpha.
~/alpha $ printf '14' > data/number.txt
~/alpha $ git add data/number.txt
~/alpha $ git commit -m '14'
[master cb51da8] 14
Ces instructions ajoutent un fichier data/number.txt (dont le contenu est 14) puis ajoutent un commit sur la branche master du dépôt alpha.
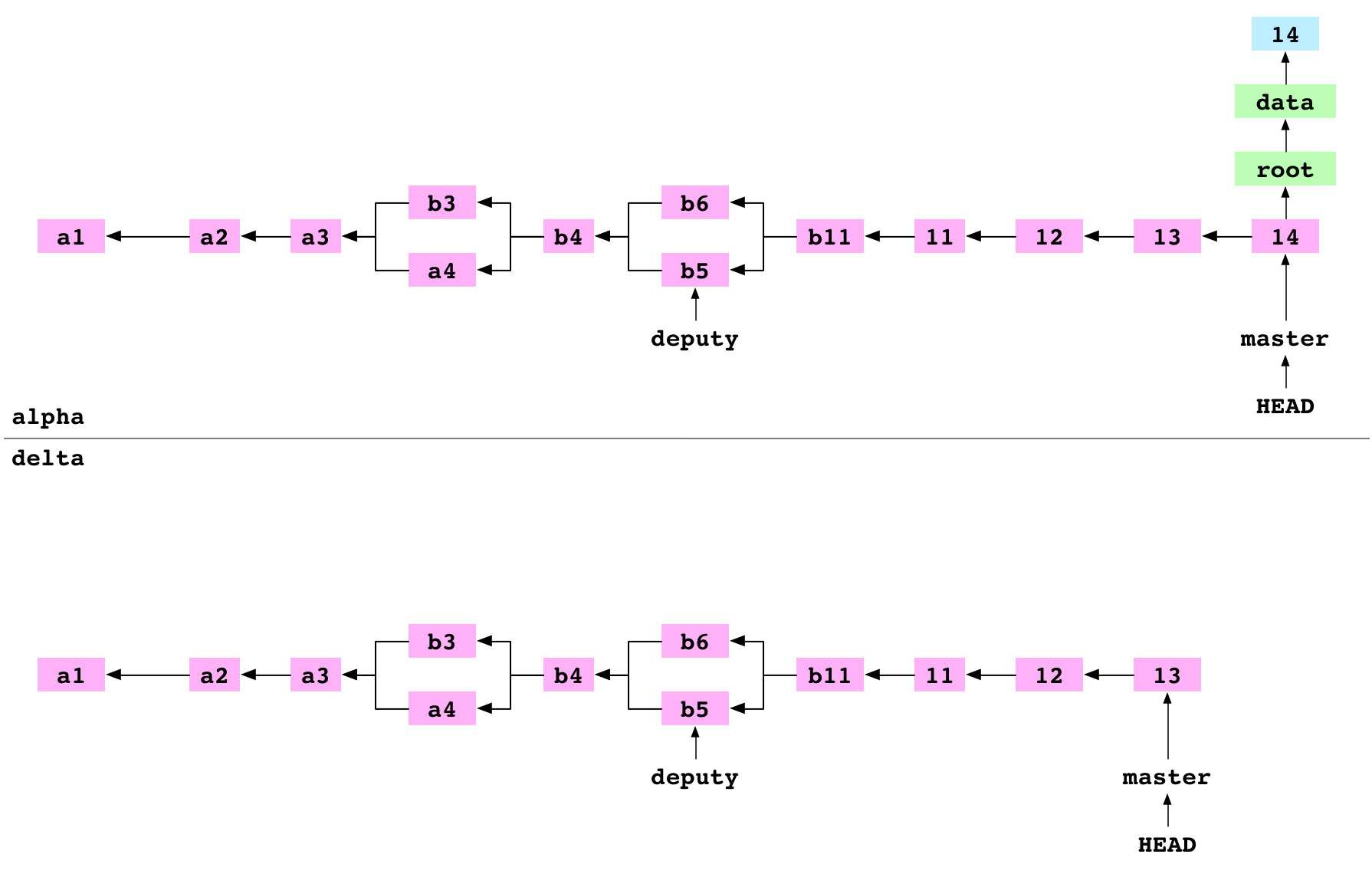
Image : Le commit 14 sur alpha
~/alpha $ git push delta master
Écriture des objets : 100%
To ../delta
3238468..cb51da8 master -> master
Ici, on pousse les données de master vers delta. Cela se fait en trois étapes.
Tout d’abord, tous les objets nécessaires au commit 14 de la branche master sont copiés de alpha/.git/objects/ vers delta/objects.
Ensuite, delta/refs/heads/master est mis à jour pour pointer au commit 14.
Troisièmement, alpha/.git/refs/remotes/delta/master pointe vers le commit 14. alpha a ainsi un état à jour de delta.
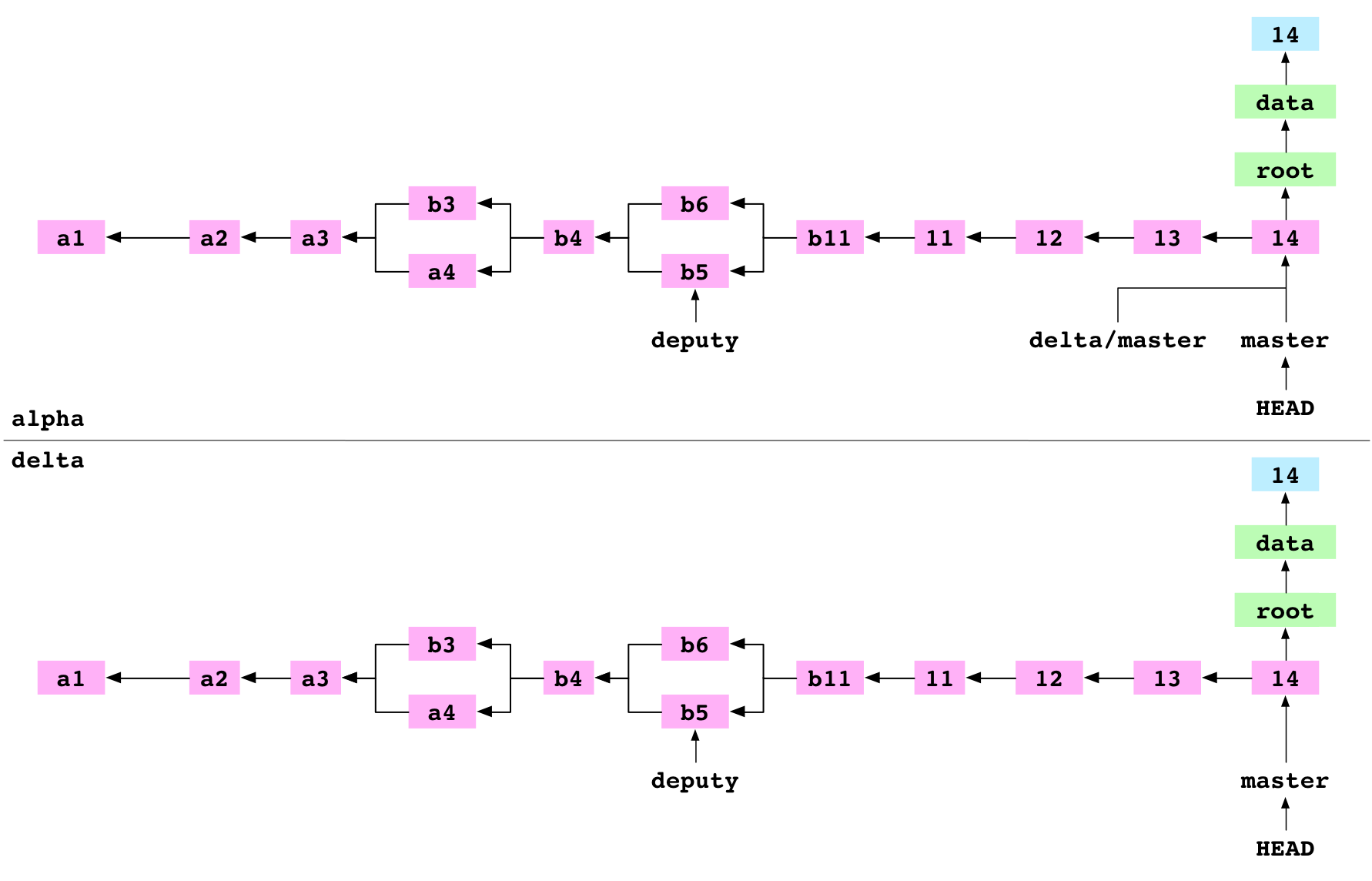
Image : Le commit 14 poussé depuis alpha vers delta
Résumé
Git est construit sur un graphe. Presque toutes les commandes Git manipulent ce graphe. Pour comprendre Git en profondeur, il faut se concentrer sur les propriétés de ce graphe et non sur des workflows ou sur des commandes.
Pour en savoir plus sur Git, examinez le répertoire .git. Ce n’est pas forcément effrayant. Regardez à l’intérieur. Changez le contenu des fichiers et regardez ce qui se passe. Créez un commit à la main. Essayez et regardez comment vous pouvez mettre un dépôt sens dessus dessous. Ensuite, réparez-le.
-
Dans ce cas, l’empreinte est plus longue que le contenu. Mais tous les morceaux de contenu plus longs que le nombre de caractères dans l’empreinte seront exprimés de façon plus concise que l’original. ↩
-
Il y a une chance que deux contenus différents aient la même empreinte mais les probabilités sont faibles. ↩
-
git prunesupprime tous les objets qui ne peuvent êtres atteints depuis une référence. Si un utilisateur utilise cette commande, il peut perdre du contenu. ↩ -
git stashsauvegarde toutes les différences entre la copie de travail et le commitHEADdans un endroit sûr. Elles peuvent être retrouvées plus tard. ↩ -
La commande
rebasepeut être utilisée afin d’ajouter, éditer ou supprimer des commits dans l’historique du dépôt. ↩
